Uso de Inteligencia Artificial para clasificación con la técnica de Árbol de Decisión


En este tutorial aprenderemos cómo la clasificación a través de la técnica del Árbol de Decisión puede construir y también mejorar medidas de selección de atributos de una base de datos utilizando el paquete de Python Scikit-learn.
Supongamos que eres responsable del sector de Marketing y te diriges a un conjunto de clientes que tienen más probabilidades de comprar su producto. De esta forma, puedes optimizar tu presupuesto publicitario identificando a tu público objetivo. Como oficial de préstamos, debes identificar las solicitudes de préstamo de alto riesgo para reducir la tasa de incumplimiento.
Este procedimiento de categorizar a los clientes como potenciales o no prospectos, o clasificar las solicitudes de préstamo como seguras o riesgosas, se conoce como desafío de clasificación.
La clasificación es un proceso de dos fases: una fase de aprendizaje y una fase de previsión. En la fase de aprendizaje, el modelo se desarrolla con base en los datos de entrenamiento proporcionados. En la fase de previsión, el modelo se aplica para estimar las respuestas en función de los datos proporcionados.
Un árbol de decisión se encuentra entre los algoritmos de clasificación más simples y populares utilizados para comprender e interpretar datos. Este algoritmo se puede utilizar tanto en problemas de clasificación como en problemas de regresión.

¿Cómo funciona el algoritmo del árbol de decisiones (AD)?
Entre los algoritmos de aprendizaje supervisado, AD puede considerarse uno de los más simples y se describe como una colección de reglas de SÍ... ENTONCES (QUINLAN, 1986; MITCHELL, 2010).
Debido a esto, los AD se han utilizado ampliamente en tareas de clasificación, ya que son una forma efectiva de construir clasificadores que predicen clases en función de los valores de los atributos que exponen los modelos. De esta forma, pueden ser utilizados en diversas aplicaciones como diagnósticos médicos y análisis de riesgo crediticio, entre otros ejemplos.
La clave del éxito de un algoritmo AD es cómo generar el árbol, es decir, cómo elegir los atributos más significativos para generar las reglas y cuáles se pueden descartar del árbol (MITCHELL, T. M. 2010). Un buen concepto está en la generación del DA a partir de la relevancia de sus particularidades, es decir, de sus atributos.
De esta forma, el atributo más significativo será el que esté en la raíz del árbol. Por lo tanto, se puede utilizar un número menor de reglas para resolver un problema dado. Según Araújo et al. (2018), considerando que los anuncios se construyen en función de la importancia de cada atributo, no siempre utilizan todos los atributos que reflejan un estándar para generar el conjunto de reglas, trayendo el beneficio de reducir el tiempo computacional en la clasificación de tareas.
Entre los algoritmos AD se encuentran ID3 (QUINLAN, 1986; MITCHELL, 2010), C4.5 (QUINLAN, 1993) y CART (BRAMER, 2007), siendo el primero de los más básicos. El algoritmo C4.5 construye el AD a partir de un conjunto de datos de la misma manera que el algoritmo ID3, utilizando el concepto de entropía y ganancia de información para definir la importancia de los atributos, como se muestra en las ecuaciones 1 y 2.
En cada nodo del árbol, el algoritmo C4.5 elige el atributo que mejor divide el conjunto de muestras en subconjuntos, tendiendo a una categoría u otra. Se elige el atributo con mayor ganancia de información normalizada para tomar la decisión (QUINLAN, 1993).
Para realizar el cálculo de la ganancia de información, primero se obtiene la entropía. La entropía de un conjunto se puede definir como el grado de pureza de ese conjunto. Dado un conjunto de entrada S que puede tener n clases distintas, la entropía de S viene dada por:
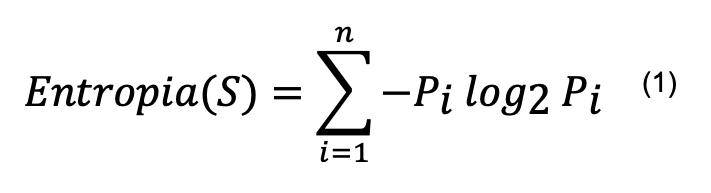
Donde Pi es la proporción de datos en S que pertenecen a la clase i.
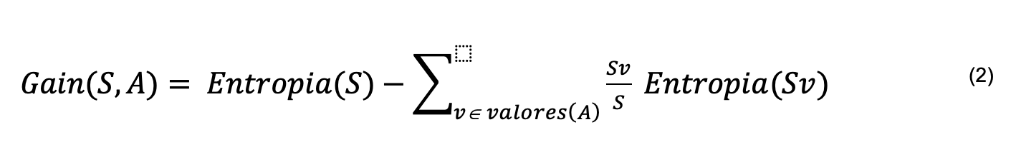
V es un elemento de los valores que puede asumir el atributo A y Sv es el subconjunto de S formado por los datos donde A=V.
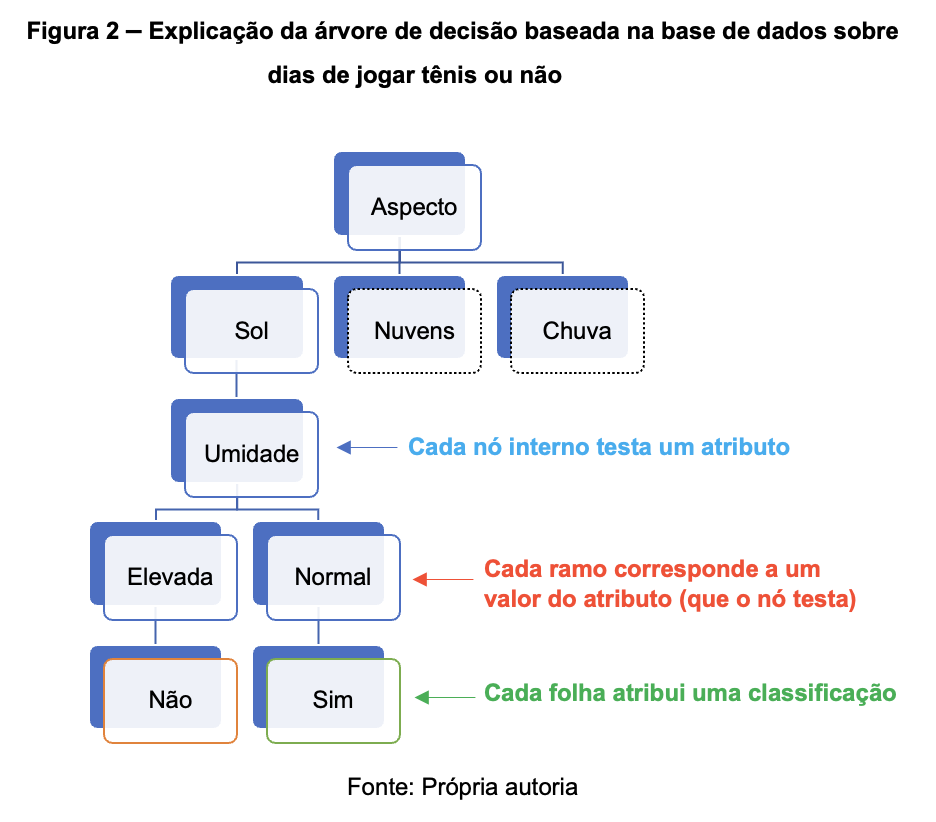
Este método de categorización se puede entender fácilmente a través del siguiente ejemplo: Supongamos que el objetivo es determinar si voy a jugar tenis. Para ello, es necesario tener en cuenta ciertos elementos del entorno como el aspecto del cielo, la temperatura, la humedad y el viento. Cada uno de estos atributos tiene varias opciones.
Por ejemplo, para la temperatura podría considerarse Templada, Fría o Cálida. La decisión de Sí (jugar al tenis) o No (no jugar al tenis) es el resultado de la categorización. Para crear la Estructura de Decisión para la práctica del Tenis, se consideran ejemplos previos (días). La Tabla 1 a continuación demuestra el ejemplo citado.
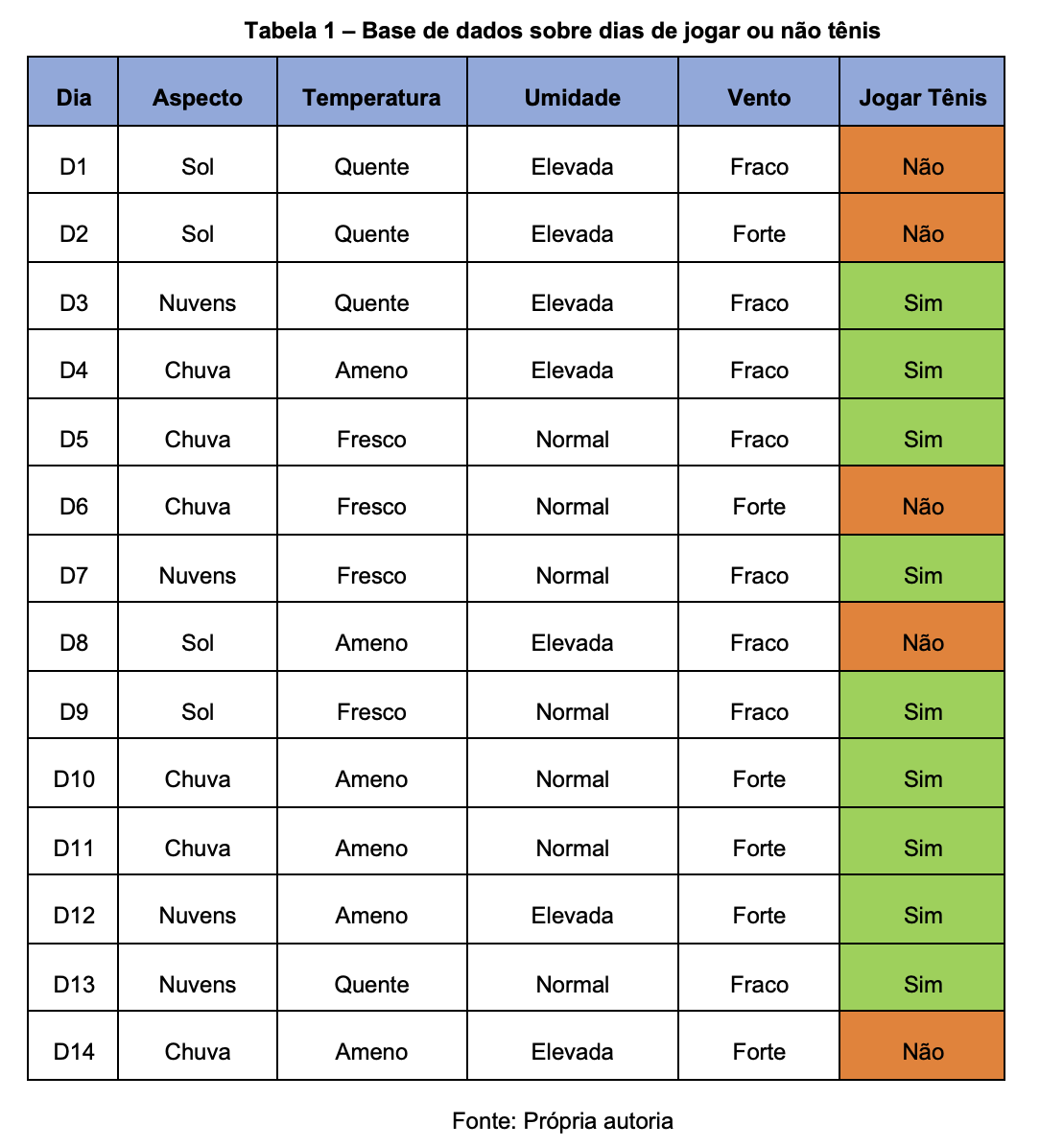
Usando estos ejemplos, es posible construir el siguiente árbol de decisión:
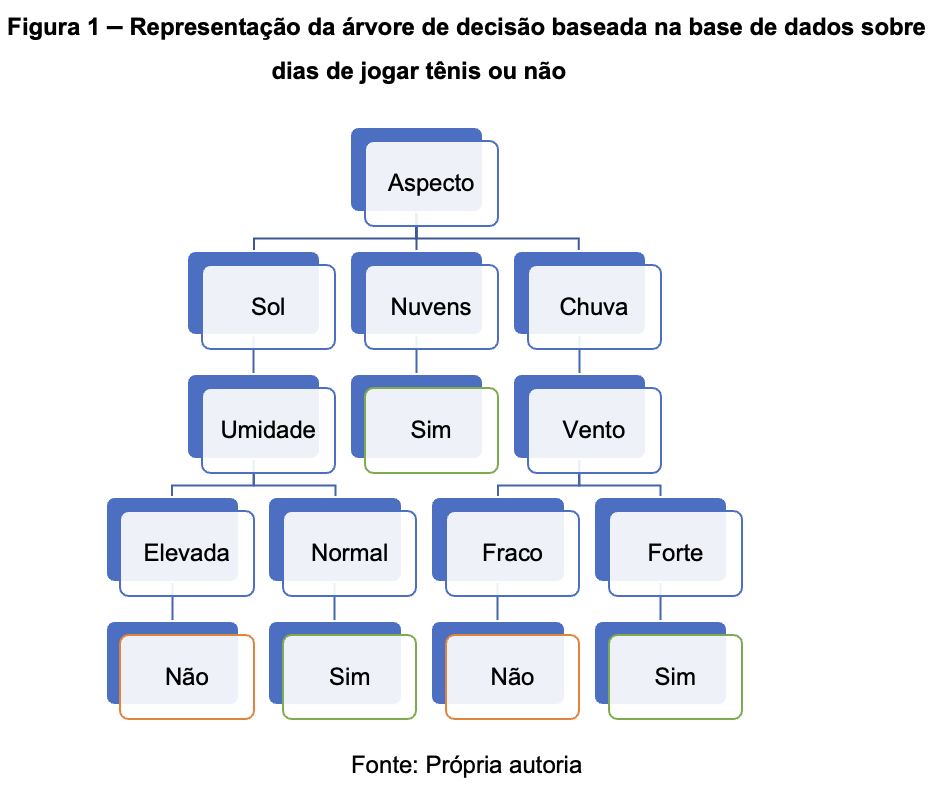
A relação entre os elementos da árvore (nós e folhas) e os atributos (valores e classificações), pode ser entendida na imagem a seguir:
Codificación
Para comenzar a construir nuestro clasificador de árboles de decisión, usaremos Scikit-learn como base importando algunas bibliotecas necesarias.

Descarga de la base de datos para la clasificación
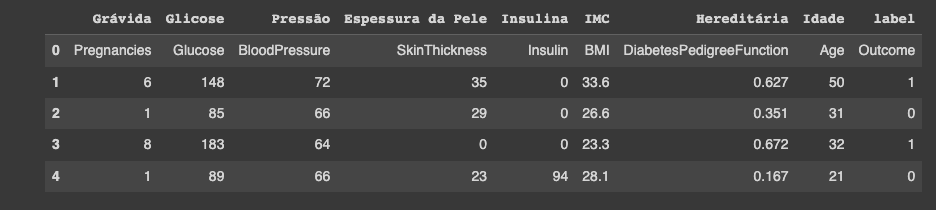
Primero descargamos el conjunto de datos Pima Indian Diabetes, necesario para usar la función de read CSV de los pandas (pd.read_csv). La base de datos puede ser descargada del sitio de Kaggle.
Sobre la base de datos
Contexto
Este conjunto de datos proviene originalmente del Instituto Nacional de Diabetes y Enfermedades Digestivas y Renales. El propósito del conjunto de datos es predecir de forma diagnóstica si un paciente tiene o no diabetes, en función de ciertas medidas de diagnóstico incluidas en el conjunto de datos.
Se impusieron varias restricciones en la selección de estas instancias de una base de datos más grande. En particular, todos los pacientes aquí son mujeres de al menos 21 años de edad que son de ascendencia indígena pima.
Contenido
Los conjuntos de datos constan de varias variables predictivas médicas y una variable de resultado. Las variables predictivas incluyen el número de embarazos que ha tenido la paciente, su IMC, nivel de insulina, edad, etc.





Cómo optimizar el desempeño del árbol de decisión
- Criterion: Nos permite utilizar diferentes medidas de selección de atributos como "gini" para el índice de Gini y "entropía" para obtener información.
- Splitter: Nos permite elegir la estrategia de división como best o random que hace la mejor división al azar.
- Max_depth: Permite elegir la profundidad máxima del árbol de decisión.


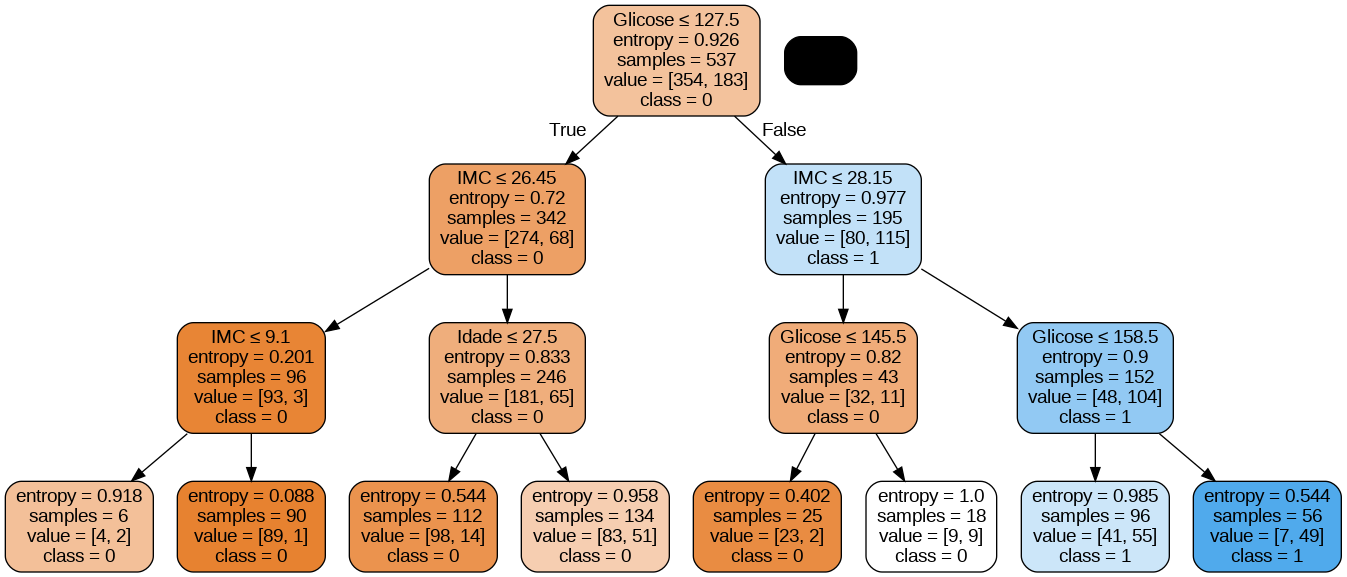
Precisión: 0.7705627705627706.
La tasa de acierto de la clasificación obtenida fue del 77,05%, lo que se considera como buena. Pero podemos mejorarla ajustando los parámetros en nuestro algoritmo de árbol de decisión.
Imprimiendo el árbol de decisión
Puede usar la función export_graphviz de Scikit-learn para mostrar el árbol de decisiones usando Colab o Jupyter Notebook. Para representar el árbol, también es necesario instalar graphviz y pydotplus, usando los comandos a continuación.

La función export_graphviz convierte el clasificador del árbol de decisión en un archivo de puntos y pydotplus convierte este archivo de puntos en formato png o visible en Colab o Jupyter.
Puntos positivos de los árboles de decisión
- Son fáciles de visualizar e interpretar para cualquier persona.
- Su tiempo de preprocesamiento es mucho menor que otros algoritmos debido a la falta de normalización de datos.
- Se pueden utilizar para la ingeniería de recursos, como la predicción de valores perdidos, adecuada para la selección de variables.
- El árbol de decisiones no hace suposiciones sobre la distribución debido a la naturaleza no paramétrica del algoritmo.
Puntos negativos de los árboles de decisión
- Este algoritmo es sensible a los datos con ruidos o detalles.
- Incluso pequeñas variaciones en los datos pueden dar como resultado un árbol de decisión diferente.
- Los árboles de decisión están sesgados con el conjunto de datos sin una extracción de datos previa adecuada.
- Los árboles muy profundos y complejos pueden volverse difíciles de interpretar y propensos a errores debido a las variaciones en los datos.

Conclusión
Espero que hayas disfrutado el artículo sobre esta técnica de Inteligencia Artificial. En futuros artículos podemos hablar de técnicas de minería de datos y el uso de otros algoritmos de inteligencia artificial y su uso en el día a día por parte de las empresas.
Referencias
- BRAMER, M. Principles of data mining. Springer, London. (2007).
- MITCHELL, T. M. Machine Learning. New York: McGraw-Hill. (2010).
- QUINLAN, J. R. Induction of decision trees. Machine Learning, 1(1):81-106. (1986).
- UCI Machine Learning, Pima Indians Diabetes Database. Predict the onset of diabetes based on diagnostic measures. Kaggle, 2018. Disponible en: https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database. Acesso en: 23 de junio de 2023.
Listopro Community da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.