Usando scraping con Node.js para categorizar currículums en PDF y separarlos en carpetas

El mundo digital es un vasto repositorio de información en diversos formatos, y los archivos PDF (Formato de Documento Portátil) son ampliamente utilizados para compartir contenido de manera confiable y estandarizada. Sin embargo, manipular y extraer datos específicos de archivos PDF puede ser un desafío, especialmente cuando el objetivo es automatizar estos procesos en un entorno de desarrollo.
En este sentido, el lenguaje de programación Node.js se presenta como una herramienta eficaz para superar estos desafíos. Este tutorial fue creado para guiarte a través de este proceso, utilizando la poderosa plataforma de programación Node.js junto con la biblioteca "pdf-parse". Con Node.js, es posible construir un código eficiente para leer archivos PDF y extraer la información relevante contenida en ellos. Además, exploraremos cómo integrar esta funcionalidad con una base de datos PostgreSQL, lo que permitirá almacenar y organizar los datos extraídos de los archivos PDF.
Así que, sigue leyendo para explorar, con mayor precisión, la posibilidad de extraer datos de archivos PDF utilizando Node.js, enriqueciendo tus habilidades de desarrollo con otra herramienta valiosa en tu repertorio.
Antes de adentrarnos en el tema, es indispensable preparar el entorno adecuado. Asegúrate de tener Node.js instalado en tu sistema, ya que servirá como base para la construcción del código. Si no tienes Node.js, puedes descargarlo e instalarlo fácilmente desde el sitio oficial de Node.js (https://nodejs.org/).
Una vez que tengas Node.js instalado, crearemos un nuevo directorio para nuestro proyecto e instalaremos las bibliotecas necesarias. npm, que es el gestor de paquetes estándar de Node.js, nos ayudará en esta tarea. Las bibliotecas fs y path son recursos nativos de Node.js y se utilizan para la manipulación de archivos y rutas de directorios, respectivamente, mientras que la biblioteca pdf-parse será nuestra opción para extraer el texto de los archivos PDF.
Este tutorial explora la creación de un programa en Node.js para la organización automatizada de archivos en carpetas, basándose en palabras clave. Este enfoque ofrece una solución práctica y eficaz para organizar documentos, resultando en un ahorro considerable de tiempo. Al implementar el código en la terminal, el usuario solo necesita definir la cantidad de categorías deseadas y las palabras clave correspondientes. De esta forma, el proceso de categorización y organización de archivos PDF se vuelve rápido, eficiente y altamente personalizable, adaptándose a las necesidades individuales de cada proyecto.
Ahora que comprendemos la importancia de este tutorial y el contexto en el que se inscribe, podemos avanzar con el paso a paso detallado de la implementación. Vamos a explorar cada aspecto del código, desde la interacción con el usuario hasta la categorización de los archivos PDF y su organización en carpetas.
Prepárate para adentrarte en el mundo de la automatización y la eficiencia proporcionado por Node.js y la biblioteca pdf-parse.

Con las dependencias instaladas, es hora de poner en práctica la implementación del código. Crearemos un script en Node.js que leerá todos los archivos PDF de un directorio específico y extraerá los datos relevantes de cada PDF utilizando la biblioteca pdf-parse.
Dentro del código, utilizaremos funciones asíncronas y promesas para garantizar que las operaciones se ejecuten de manera eficiente y sin bloquear el flujo del programa.
Paso 1: Configuración Inicial
Primero, verifica si tienes Node.js instalado en tu sistema. En caso de que no lo tengas, puedes descargarlo e instalarlo desde los sitios oficiales:
- Node.js: https://nodejs.org/
Una vez que tengas Node.js instalado, crea una carpeta llamada “currículos” en el mismo directorio donde estará el script.
Dentro de la carpeta “currículos”, coloca los archivos PDF que contienen la información de los currículos que vas a utilizar.
Luego, ejecuta el siguiente comando para crear el archivo package.json e instalar las dependencias necesarias:
Paso 2: Instalación de Dependencias
Ahora instalaremos las bibliotecas necesarias. Ejecuta el siguiente comando en la terminal:
Explicación de las dependencias:
- fs: Módulo nativo de Node.js para manejar operaciones de archivos.
- path: Módulo nativo de Node.js para manipular rutas de archivos y directorios.
- readline: Módulo nativo de Node.js que facilita la lectura de entradas del usuario desde la línea de comando.
- pdf-parse: Biblioteca para extraer texto de archivos PDF.
Paso 3: Implementación del Código
Ahora es el momento de implementar el código. Crea un archivo llamado ‘node index.js’ y agrega el siguiente código:
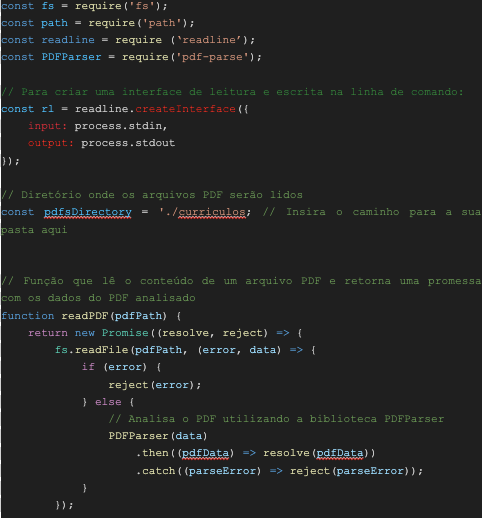
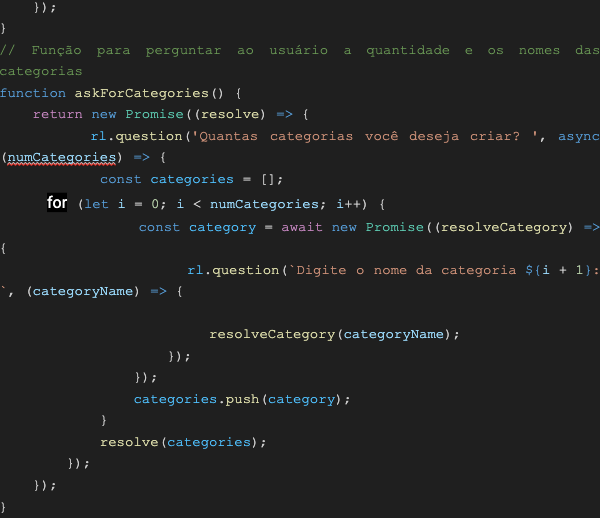
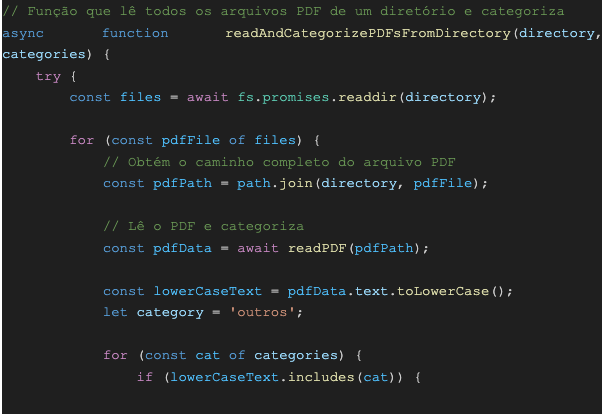
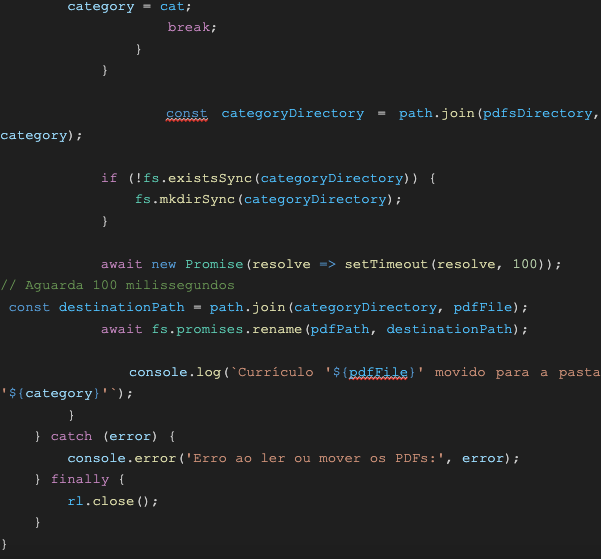
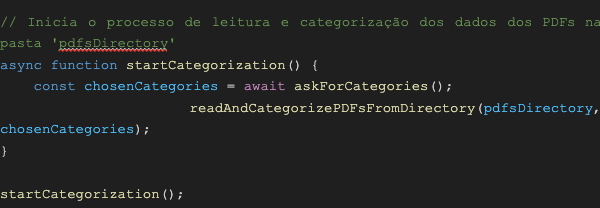
pdfsDirectory: Es la ruta del directorio donde se leerán los archivos PDF. En el código actual, los archivos PDF deben estar en la carpeta ./curriculos (en la misma carpeta que el script).
askForCategories: Esta función solicita al usuario la cantidad y los nombres de las categorías que se usarán para organizar los archivos PDF.
startCategorization: Función cuyo objetivo es iniciar el proceso de categorización. Llama a la función anterior (aksforcategories) para obtener las categorías definidas por el usuario y luego llama a la función “readAndCategorizePDFsFromDirectory” para categorizar los archivos PDF.
readPDF: Función responsable de leer el contenido de un archivo PDF y devolver una promesa que contiene los datos del PDF analizado.
readAndCategorizePDFsFromDirectory: Esta función tiene como propósito leer todos los archivos PDF del directorio y categorizarlos con base en las palabras clave encontradas en su contenido.
Paso 4: Ejecutando el Programa
Ahora, abre la terminal y escribe el siguiente comando:
“node index.js”
Para ilustrar la ejecución del programa y la categorización de los currículos, le pedí al programa que separara los archivos seleccionados en cuatro categorías: front end, back end, full stack y CSS. Lo que no se ajuste a estas palabras clave será separado en una carpeta llamada “otros”:

Después de la categorización, realizada de forma interactiva con el usuario desde la terminal, el programa muestra cómo quedaron organizados los currículos en las carpetas, de acuerdo con los criterios solicitados por el usuario:
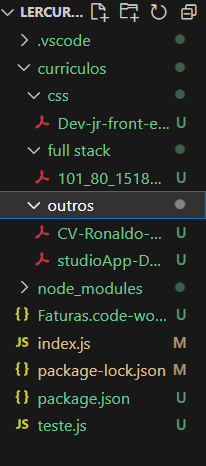
De esta manera, el programa identificó las palabras clave solicitadas y, tras categorizar los archivos PDF, creó una carpeta correspondiente a cada categoría. Los archivos que no cumplieron con los requisitos solicitados fueron movidos a una carpeta llamada "otros". Con este código, puedes mejorar y personalizar los archivos según tus necesidades.
Conclusión
En este tutorial, el objetivo fue presentar una solución eficaz para quienes buscan automatizar procesos de organización de archivos en formato PDF, con la creación de un programa en Node.js que automatiza la clasificación de archivos en carpetas basadas en palabras clave.
A lo largo de este tutorial, exploramos un escenario práctico en el que la automatización de tareas demostró ser una solución poderosa y eficiente. Al utilizar el lenguaje de programación Node.js y la biblioteca pdf-parse, fuimos capaces de desarrollar un programa que extrae información relevante de archivos PDF y los clasifica de acuerdo con palabras clave específicas. Este proceso no solo simplificó la organización de documentos, sino que también ahorró un tiempo valioso que pudo ser destinado a tareas más estratégicas.
El tutorial comenzó con una introducción que abordaba la importancia de los archivos PDF en el mundo digital y los desafíos de manipularlos. Discutimos la preparación del entorno de desarrollo, incluida la instalación de Node.js y las bibliotecas necesarias. Luego, detallamos el código paso a paso, explicando cada función y componente involucrado. La incorporación de la interacción con el usuario a través de readline ofreció una experiencia más amigable y personalizada para la aplicación.
El punto central del tutorial fue la creación de la función que lee y clasifica los archivos PDF en función de las palabras clave definidas por el usuario. La automatización de este proceso resultó en una ganancia significativa en eficiencia, reduciendo la necesidad de intervención manual repetitiva. Este enfoque puede aplicarse en diversos escenarios, desde la organización de currículums hasta la clasificación de documentos comerciales.
Al final, discutimos brevemente el concepto de automatización, destacando su relevancia para optimizar tareas rutinarias y liberar recursos para actividades más estratégicas y creativas. A través de este tutorial, no solo aprendiste a crear un programa funcional, sino que también comprendiste la importancia de automatizar tareas en diversos contextos.
En resumen, la automatización es una herramienta valiosa en el mundo moderno, y este tutorial ofreció un ejemplo práctico de cómo puede implementarse mediante la programación. Esperamos que hayas adquirido conocimientos útiles e inspiración para explorar más a fondo las posibilidades de la automatización en tus actividades diarias y proyectos futuros.
El proceso de organización de archivos, cuando se realiza manualmente, puede ser extremadamente largo, especialmente cuando hay una cantidad abrumadora de documentos para clasificar y organizar en carpetas. Al implementar el código desarrollado y presentado en este tutorial, este proceso puede simplificarse con un comando en la terminal, donde los usuarios solo necesitan proporcionar la cantidad de categorías deseadas y las palabras clave que se utilizarán para clasificar los archivos.
Este enfoque ofrece numerosos beneficios, como la reducción de errores y la optimización del flujo de trabajo, además de una mejor gestión de nuestro tiempo, permitiendo que el programa automatice tareas repetitivas y propensas a errores. De este modo, el usuario puede concentrarse en tareas más creativas y estratégicas.
Por lo tanto, si estás buscando optimizar la organización de documentos, este tutorial puede ser la solución práctica y accesible. Ahora tienes en tus manos una herramienta poderosa para automatizar la clasificación de archivos PDF con base en criterios definidos, ahorrando tiempo y haciendo que la actividad sea más eficiente.
El tiempo ahorrado a través de esta automatización es invaluable, ya que libera al usuario para dedicarlo a actividades más productivas. A medida que profundizamos en la programación y desarrollamos soluciones más complejas, el conocimiento adquirido aquí servirá como una base sólida para futuros proyectos.
En el contexto del desarrollo de software, la automatización desempeña un papel crucial, mejora la calidad del código y acelera el ciclo de desarrollo. Muchas tareas pueden automatizarse y utilizarse ampliamente en las actividades rutinarias del día a día.
Finalmente, puedes avanzar con confianza, sabiendo que la automatización tiene un poderoso potencial en términos de productividad y aplicabilidad en varios contextos. Espero que este tutorial te haya inspirado a explorar más a fondo las capacidades de Node.js y a crear soluciones inteligentes para desafíos del mundo real.

Referencias Bibliográficas
- Documentación oficial de Node.js: https://nodejs.org/
- Documentación de la biblioteca pdf-parse: https://www.npmjs.com/package/pdf-parse
- Documentación de la biblioteca fs (Node.js): https://nodejs.org/api/fs.html
- Documentación de la biblioteca path (Node.js): https://nodejs.org/api/path.html
- Documentación de la biblioteca readline (Node.js): https://nodejs.org/api/readline.html
Listopro Community da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.