Tu primer modelo de Inteligencia Artificial: área Salud


Gracias a la revolución del hardware ya existe la capacidad computacional para realizar operaciones algebraicas complejas, base de la inteligencia artificial. Ahora podemos programar desde algoritmos simples como regresiones lineales o Fuzzy Logic (utilizado en la programación de las lavadoras), hasta procesamientos de lenguaje natural como Siri de Apple o Alexa de Amazon. Además, y como parte de una política de democratizar el aprendizaje, ya no es necesario contar con una supermáquina para programar con GPU o TPU, sino que podemos utilizar recursos gratuitos en línea como Google Colab o DeepNote para sumergirnos en el apasionante mundo de la Inteligencia Artificial.
Inteligencia Artificial en el área de Salud
El uso del aprendizaje automático se ha extendido a diferentes áreas como la industria automotriz (con autos inteligentes) o la del streaming, con algoritmos que aprenden constantemente de nuestros gustos, por lo que sus recomendaciones son personalizadas y acertadas. En el área de Salud, el proyecto más conocido es, probablemente, el de IBM Watson Health, ahora conocido como Merative, el cual tiene importantes avances en el diagnóstico de enfermedades y sus tratamientos.
Desarrollar software para predicción de enfermedades no es algo nuevo. Existen investigaciones en el PSG College of Arts and Science para predecir enfermedades del corazón con algoritmos Naive Bayes y Support Vector Machine, con una precisión mayor al 70% [1]. Naive Bayes es un algoritmo de clasificación de Machine Learning basado en el teorema estadístico de Bayes. Support Vector Machine es un algoritmo de aprendizaje supervisado que se utiliza para regresión y clasificación.
Otro de los retos actuales para investigadores es el diagnóstico temprano de retinopatía diabética, una complicación de la diabetes que afecta la vista. El dataset consiste en imágenes del interior del ojo, tomadas por una cámara especial. El procesamiento abarca la detección, segmentación de la gravedad y localización en puntos de referencia para la detección de retinopatía, a través de métodos estadísticos, métodos de clasificación, redes neuronales artificiales, Deep Learning, entre otros [2].
En este artículo, trabajaremos un dataset público alojado en Kaggle, que consta de 27 preguntas sobre la salud mental en la industria tech. De igual forma, realizaremos un modelo de clasificación con K-means, un algoritmo de aprendizaje no supervisado cuyo objetivo es agrupar datos a partir de sus características.
Hacia el entorno de trabajo
Para este tutorial utilizaremos el entorno de trabajo que nos proporciona Google Colab.
Importamos el drive y conectamos con el entorno de ejecución, con lo que te pedirá permisos de acceso.

Por otra parte, para el proyecto utilizaremos el dataset Mental Health in Tech Survey de Kaggle. Para descargarlo, es necesario crear una cuenta en la plataforma, para luego acceder a account. Navegamos hasta la opción de API, donde le daremos clic en Create New API Token y se descargará de manera automática un archivo llamado kaggle.json, el cual guardaremos en una carpeta dentro de nuestro Drive.


A continuación, utilizamos la librería os para navegar entre nuestros archivos y, posteriormente, guardamos el archivo kaggle.json en la carpeta de nuestra preferencia dentro de nuestra unidad de Drive.

Una vez dentro, navegamos con el comando %cd al path donde está guardado nuestro archivo kaggle.

Con lo anterior ya es posible descargar el dataset Mental Health in Tech Survey. Accede al link y busca los 3 puntitos a la derecha para copiar el comando de la API.

Una vez copiado, lo pegas en la siguiente celda de tu notebook en Colab. No olvides poner un “!” por delante para descargar el archivo en tu directorio.

¡Perfecto! Ahora es necesario descomprimir el archivo descargado mental-health-in-tech-survey.zip, con el método !unzip. Si lo crees pertinente, puedes crear una carpeta específica para guardar los datos descomprimidos.

Preprocesamiento de datos
Ya con el archivo descomprimido y los datos en formato csv podemos explorarlos y manipularlos con ayuda de la librería Pandas. Por lo tanto, importamos la librería en nuestro notebook.

Guardamos el archivo como dataframe en la variable df y leemos el archivo csv con el método de pandas read_csv. Después copiamos dentro del paréntesis el directorio y el archivo csv dentro de comillas simples ‘’. El método df.head (5) nos permite visualizar las cinco primeras columnas del dataset:


El método df.tail() nos permite visualizar las últimas cinco columnas.

El método df.columns muestra las 27 columnas de nuestro dataset.

Utilizamos el método df.describe ya que permite tener una descripción estadística del dataset. En este caso, solo considera las métricas para la columna de Age, ya que es la única columna con datos continuos. Las otras 26 columnas son datos discretos, en este caso categóricos.

Para realizar un análisis por columna, utilizamos el método value.counts con la variable ‘supervisor’ y observar su comportamiento, obteniendo 516 datos para yes, 393 para no, y 350 para Some of them. De esta manera, podemos analizar todas las variables discretas.

Para finalizar con el preprocesamiento de datos, eliminamos con el método de Pandas drop las columnas que no utilizaremos en el análisis. En este caso, serían Timestamp, porque en este análisis la fecha es irrelevante, Country y State porque no vamos a sesgar por región geográfica. También eliminaremos Obs_consequence porque, de acuerdo con el dataset, esta pregunta este campo está relacionada con que el encuestado haya escuchado u observado algún comportamiento negativo relacionado con la salud mental de algún compañero de trabajo dentro de su espacio. Dado que en este tutorial no vamos a abordar ese análisis, eliminamos de igual forma la columna Comments, un campo donde los encuestados pueden explayarse, lo cual generaría ruido en nuestro análisis al no ser una variable discreta o continua.
Al eliminar estas variables, ejecutamos un trabajo superficial de cleaning data que realiza un científico de datos. Este proceso consiste en corregir o eliminar datos incorrectos o que no estén en el formato establecido. No existe una forma preestablecida de cómo realizar esta limpieza ya que los procesos varían de un proceso a otro. En este artículo eliminamos las columnas de Timestamp, Country, State, Obs_consequece y Comments porque no realizaban una contribución a la prognosis del análisis de datos.
Los parámetros axis e inplace deben estar definidos o el método tomará valores predeterminados y no se eliminarán ninguna de las columnas seleccionadas. Para más información, consulta con la documentación oficial de Pandas.

Implementación del algoritmo K-means
Para este tutorial nos apoyaremos en Pycaret, una librería de código abierto que permite trabajar algoritmos de Machine Learning con poco código, además de ser intuitiva y una gran herramienta para escoger modelos. Otras opciones para trabajar algoritmos de Machine Learning serían Tensorflow y Pytorch, ambas muy populares y con una excelente comunidad, especialmente en StackOverflow.
Al finalizar los pasos de este artículo seremos capaces de:
- Trabajar con datos reales importados desde la comunidad en línea de Ciencia de Datos y Machine Learning más grande y profesional del mundo.
- Configurar un entorno de trabajo Opensource, desde la preparación de los datos, hasta la instalación de la librería y configuración del módulo de clústers no supervisado de PyCaret.
- Crear un modelo y no supervisado y entrenarlo.
- Guardar los pesos del modelo para implementarlo en el futuro.
Instalamos la librería en el notebook con pip.

Es posible que salten errores al instalar Pycaret respecto a la compatibilidad de Numpy con Pycaret. Es por ello que se recomienda trabajar con una versión de Numpy de 1.21 o menos.

A continuación, Importamos en nuestro notebook pycaret.clustering. También se pueden trabajar modelos de regresión, pero en este caso solo trabajaremos con clustering.

Preparamos los datos para el modelo, guardando el dataframe en la variable data. Los valores de frac=0.9 y random_state =1, permiten dividir el dataset en un 90% para entrenar y 10% para predicciones.
Esta es una práctica común al desarrollar modelos predictivos, utilizando divisiones de 80/20, o 70/30. También se puede dividir el dataset en tres partes, un porcentaje para el entrenamiento, otro para la validación y finalmente un último porcentaje para pruebas. No existe una regla oficial de cómo se tiene que distribuir el dataset, pero se recomienda un gran porcentaje para entrenamiento. El valor de random_state permite implementar un valor semilla para la distribución del dataset.

Utilizamos el método de Pycaret setup para inicializar el proceso. En la salida de la celda observamos que solo toma una columna como numeric (en este caso age), las demás las toma como categorías. Si en algún momento se quiere trabajar estas categorías de manera numérica o booleana, en este campo se puede especificar.


El siguiente paso es crear el modelo llamado K-means. En caso de no definir el número de clusters, éste por defecto se convierte en cuatro. Como vemos en la salida de la celda, los clusters son el número de centroides en los cuales se agruparán los datos.

Para definir manualmente el número de clusters o de agrupaciones que deseamos para nuestro modelo, lo definimos dentro del método create_model, con la variable num_clusters.

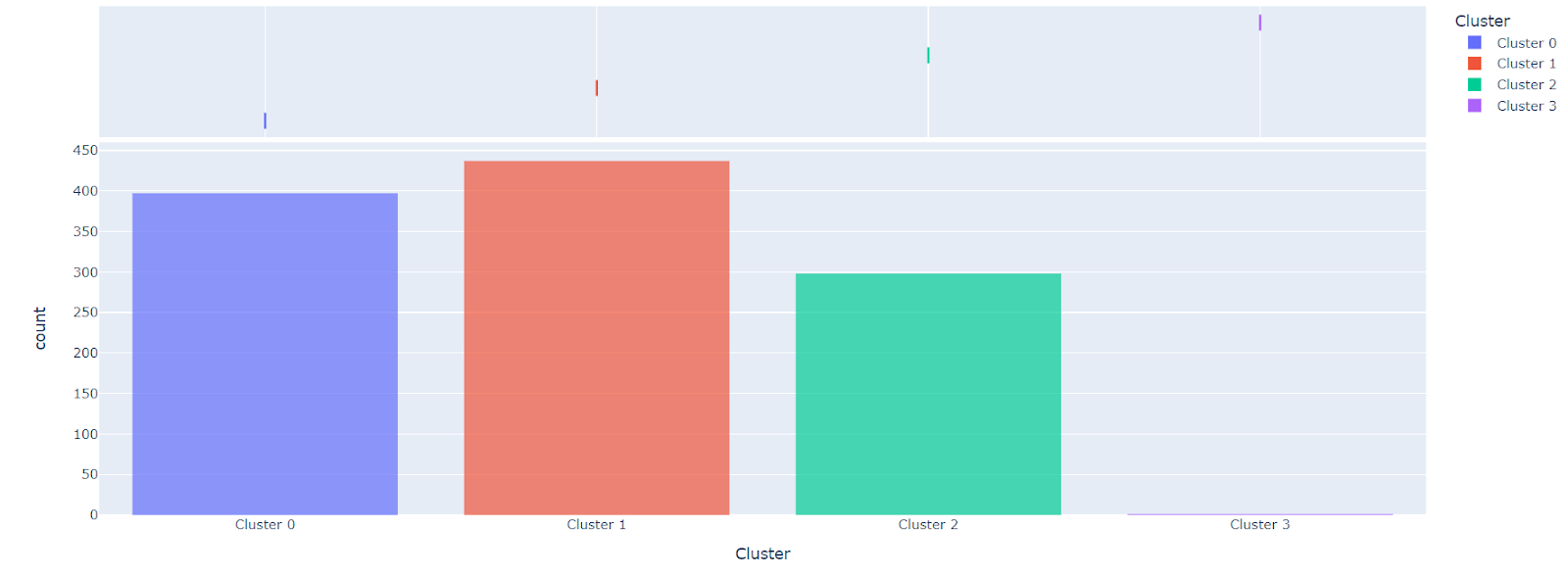
Finalmente, asignamos el modelo K-means definido previamente, sin especificar el número de clusters, por lo que tendremos 4 categorías. Al observar los resultados en kmean_results.head(), nos damos cuenta de que apareció una nueva columna llamada Cluster , donde se encuentran 4 posibles etiquetas: cluster 0, cluster 1, cluster 2 y cluster 3.


Podemos visualizar las categorías de nuestro modelo con el método plot_model . Al graficarse, existen 3 grandes grupos y uno que únicamente contiene una muestra. A partir de estos centroides podemos realizar varios análisis dependiendo de las preguntas que tengamos, respecto a nuestros clusters.

Por último, guardamos el modelo con el método save_model en el directorio actual en el que trabajamos. En este caso se llamará Final Kmeans Model 20Nov2022.

¡Felicidades! Ya sabes cómo implementar un algoritmo de agrupación de Machine Learning con las herramientas PyCaret y Google Colab, así como utilizar un dataset estructurado de Kaggle. Los siguientes pasos como AI Developer, Data Scientist, o Data Analyst son realizar una visualización de datos. Para esto puedes utilizar las herramientas de Matplotlib, Seaborn o Tableau, todas entre las más populares.
Como pudimos observar, las herramientas ya constituidas en Machine Learning como Pycaret, Tensorflow, Sklearn o Pytorch permiten la implementación de modelos de aprendizaje supervisado y no supervisado de una manera más fácil e intuitiva, lo que permite que la curva de aprendizaje no sea un impedimento para su implementación. Además, trabajamos un aprendizaje de tipo caja negra, en la cual no es necesario (pero sí recomendable) saber qué ocurre dentro del modelo. Basta con conocer los parámetros de entrada y la salida que buscamos.
La salud mental debe ser una prioridad no solo para las personas, sino para las instituciones que nos emplean. Ningún algoritmo o chatbot puede reemplazar el trabajo de un profesional médico, aunque los algoritmos nos pueden ayudar a detectar a quien necesita ayuda y dar soporte a un diagnóstico médico. El dataset es una muestra completa y representativa que puede ser explorada de múltiples maneras. Khurana et al [3] exploran otros métodos además de kmeans con el mismo dataset, por lo que les invito a leer su trabajo.
Fuentes consultadas
[1] Vembandasamy, K., Sasipriya, R., & Deepa, E. (2015). Heart diseases detection using Naive Bayes algorithm. International Journal of Innovative Science, Engineering & Technology, 2(9), 441-444.
[2] Soomro, T. A., Gao, J., Khan, T., Hani, A. F. M., Khan, M. A., & Paul, M. (2017). Computerised approaches for the detection of diabetic retinopathy using retinal fundus images: a survey. Pattern Analysis and Applications, 20(4), 927-961.
[3] Khurana, Y., Jindal, S., Gunwant, H., & Gupta, D. (2022). Mental Health Prognosis Using Machine Learning. Available at SSRN 4060009.
Documentación de Pandas: https://pandas.pydata.org/docs/
Documentación de Pycaret: https://pycaret.gitbook.io/docs/
Revelo Content Network da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.