Simplifica el webscraping con Selenium y Python


Cuando queremos obtener grandes cantidades de información o realizar pruebas sobre aplicaciones web es poco práctico realizar esta tarea de forma manual, dependiendo de tus necesidades.
Una herramienta muy utilizada para automatizar esta tarea es Selenium, un proyecto de código abierto con varias funcionalidades que permiten la automatización de navegadores con diferentes lenguajes de programación. En este artículo, veremos paso a paso cómo instalar y configurar Selenium para crear algoritmos simples de webscraping con Python.
Primero, iniciaremos un entorno virtual para instalar las librerías necesarias:

Una vez creado, activemos el entorno virtual:

Con el entorno configurado, las bibliotecas que instalaremos serán Selenium para webscraping, Decouple para configurar variables de entorno y Webdriver Manager para descargar el controlador apropiado para el navegador. Usemos el siguiente comando en la terminal:

Ahora crearemos un archivo llamado main.py e importaremos los módulos de biblioteca necesarios para el proyecto:
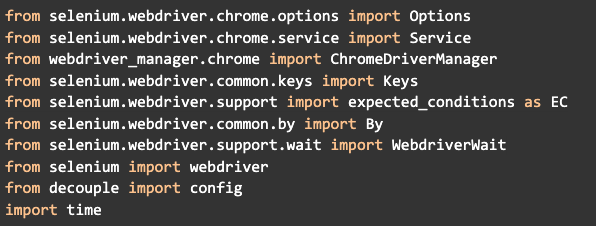
Es importante saber que cada uno de estos módulos tendrá un uso específico. El proceso de extracción de datos de un sitio no siempre es sencillo, ya que hay sitios que son estáticos y otros que son dinámicos (cambian según la interacción). Algunos cambian solo por su funcionamiento normal, mientras que otros tienen programados sistemas específicos para evitar que sean controlados por robots.
Sistemas anti-bots: ¿qué son?
Para que tu robot acceda a un sitio determinado, debes realizar una solicitud como cualquier otro usuario y luego recibir la respuesta del servidor. La diferencia entre ellos es básicamente que mientras el usuario tiene una cierta limitación para interactuar con el sitio, el robot puede seguir accediendo al sitio varias veces para extraer datos. Teniendo en cuenta que para cada solicitud es necesario que el servidor realice un determinado procesamiento para luego devolver una respuesta, esto puede escalar muy rápidamente, dejando el sitio más lento para otros usuarios que intentan acceder a él si no hay una infraestructura preparada para ello (esto podría compararse con un ataque DDOS).
Otras razones detrás del desarrollo de sistemas anti-bot serían, por ejemplo, para un sitio web de juegos en línea, donde a través de un robot que recopila datos se podría elaborar una especie de trampa. Otro ejemplo son los servicios de correo electrónico, donde sería posible crear diferentes direcciones para registrarse en diferentes servicios (por eso existe el famoso Captcha, ese sistema donde necesitas escribir una secuencia de letras, números borrosos o incluso seleccionar imágenes similares para demostrar que no eres un robot).
Existen varias técnicas para crear y eludir los sistemas anti-bot. Una forma clásica es cuando el sistema detecta que es un robot el que accede y empieza a banear la IP, algo que se puede eludir usando proxies públicos al azar.
Webscraping en el contexto de la seguridad de la información
Cabe mencionar que este juego del gato y el ratón existe desde hace mucho tiempo. Pensando en el desarrollador que está construyendo el robot, esta es una forma de obtener grandes cantidades de datos y disfrutar de servicios que no son accesibles para la mayoría de los usuarios.
El acto de webscraping en sí mismo no es un delito, ya que técnicamente solo accedemos a información disponible públicamente, pero lo que hacemos con ella es lo que puede definir si es un crimen o no, como el ejemplo de hacks en juegos, hacer algún tipo de chantaje con los datos o invadir algún sistema.
Ahora, pensando en el lado del desarrollador que diseña sistemas de defensa, la idea no es crear un sistema infalible (porque incluso los más avanzados hoy en día como ReCaptcha pueden tener sus días contados con el avance en las áreas de aprendizaje automático y visión computacional). Tener conocimiento de los ataques más frecuentes y la capacidad de desarrollar programas para evitarlos es lo de menos, pero sí que ya puedas reducir considerablemente el número de personas con habilidad y dispuestas a atacar tu sistema, lo cual ganará quien tenga más conocimiento.
Este tema de la seguridad de la información puede dar para varios artículos por sí solo, pero esta breve introducción sirve para entender el principio básico de que no existe una “bala de plata” ni para los atacantes ni para quienes se defienden. Asimismo, cuando el tema es la seguridad no se puede ser demasiado cuidadoso. Esto significa que si detectas que un sitio en particular está bloqueando tu acceso, probablemente tendrás que desarrollar tu propia solución para eludir este sistema.
Detectar sistemas de seguridad
Hay algunas formas para detectar la forma en que el sistema rastrea tus acciones. Una vez que hayas configurado tu robot -como veremos más adelante-, si en algún momento deja de funcionar puedes realizar algunas pruebas, como por ejemplo:
- Borrar cookies del navegador,
- Acceder con otro navegador,
- Acceder con otra computadora o teléfono móvil,
- Acceder usando otra red para saber si tu IP está siendo bloqueada,
- Investigar el JavaScript del sitio para ver si envía información al servidor de que el navegador está siendo controlado por un robot.
Aclarada la parte teórica, vamos a la práctica. Después de importar los módulos, comience creando un objeto de la clase Opciones (aquí es donde agregaremos la configuración para el navegador). En este caso, como estoy usando el navegador Brave, agregué la opción binary_location, donde se encuentra el ejecutable del navegador. La misma configuración funciona si está utilizando Google Chrome, ya que Brave se basa en él.

La primera opción sirve para evitar que Selenium envíe logs a tu consola, al tiempo que binary_location se configuró a través de la función config del módulo de Decouple. Esto es para que podamos escribir el valor de una variable en otro archivo llamado .env, de modo que cuando el programa se inicialice buscará ese archivo y cargará el valor en la memoria del programa. Solo haciendo un apéndice, esta forma de extraer datos de un archivo .env se usa para variables sensibles como, por ejemplo, acceder a una base de datos. Estos archivos deben excluirse cuando el código se envía a GitHub y deben declararse en .gitignore.
Otra opción que se puede agregar es --headless, que se usa para iniciar el navegador en segundo plano:

Ahora todo lo que tiene que hacer es configurar el controlador, dándole las opciones que acabamos de configurar y el servicio que es el controlador que se conectará con el navegador (el módulo ChromeDriveManager instalará el controlador automáticamente en la primera ejecución):

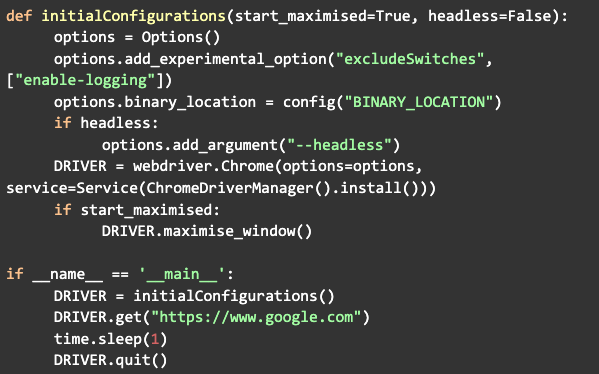
Antes de iniciar el controlador, una configuración que se puede agregar es iniciar en modo maximizado:

Ahora solo llama a la función get, pasando la URL del sitio web al que deseas acceder. Al ejecutar el navegador, éste se abrirá y realizará una solicitud al sitio web especificado. Esperamos unos segundos con el módulo time, luego cerramos el navegador por llamando a la función quit:

El siguiente paso es buscar información dentro del sitio, pero primero podemos encapsular el código que ya hemos creado en una función denominada configuración inicial, que se llamará primero cuando se inicie el código:
Ahora, para buscar el elemento que deseas, simplemente abre el navegador normalmente, coloca el mouse sobre el elemento, haz clic derecho y luego selecciona "inspeccionar elemento".
El navegador abrirá el código HTML y contendrá diferentes tipos de etiquetas HTML con sus propiedades como clase, nombre e ID (generalmente, es mejor usar la ID ya que es única). Ahora hagamos una búsqueda en Google solo para ejemplificar.
Primero verificamos los parámetros de la entrada, que se verá así:

Aquí podemos ver que el parámetro nombre tiene el valor q y este valor se usará para acceder a este elemento, así que después de get, obtengamos este elemento usando el módulo By para buscar el nombre:

Teniendo este elemento definido en una variable, podemos empezar a interactuar con él enviando un texto, por ejemplo:

Cuando se envía el texto, podemos a través del módulo Keys enviar el comando enter, que está representado por RETURN:

Luego, una vez finalizada la búsqueda, podemos hacer que el robot muestre el título de cada enlace. Para ello, analicemos nuevamente la estructura del HTML. Si abres las búsquedas de Google, haz clic derecho en un título y luego inspecciona. Verás algo como esto:

Cada uno de estos grupos de letras y números separados por espacios son las clases de ese elemento. Algunos sitios web son más fáciles de leer el nombre de las clases y otros no. Para saber cuál clase es específica de los elementos del mismo tipo que buscamos, podemos probar cada una.
Entonces, de la misma manera que hicimos con el cuadro de texto para buscar, lo haremos para encontrar los títulos. La diferencia es que en lugar de usar find_element usaremos find_elements para encontrar más de un elemento al mismo tiempo, devolviendo un lista. Luego, para cada elemento, podemos mostrar su texto en la terminal con un loop:

Otra forma recomendada de buscar un elemento es usando el WebDriverWait que importamos allí al principio, porque muchas veces la página puede cargar, pero el elemento sigue sin verse. Entonces, el siguiente comando esperará una cierta cantidad de tiempo hasta que las condiciones esperadas sean válidas:
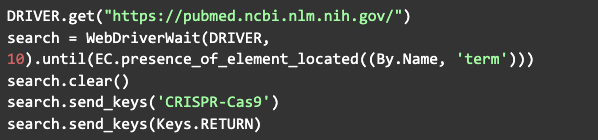
Lo que básicamente hace este comando es acceder al sitio web de pubmed, encontrar y seleccionar la barra de búsqueda, ingresar el término que se busca y presionar enter. Esta instrucción sirve solo como un ejemplo de lo que se puede hacer. En la práctica, existe otra forma más eficiente de investigar en ciertos sitios, a través de la manipulación de la URL. Por ejemplo, el siguiente comando tendría el mismo efecto que el anterior:

Otra opción de interacción es hacer clic en un elemento:

En el ejemplo anterior, estamos haciendo clic en el primer artículo que aparece en la búsqueda. En este caso funciona, pero puede haber casos en los que hacer clic con Python pueda generar un error, por lo que podemos ejecutar comandos a través de JavaScript de la siguiente manera:

Además de éstas, hay varias otras funciones de cada uno de los módulos que importamos y pueden ser utilizadas para diferentes propósitos. Con el conocimiento adquirido en este artículo ya tienes una base y puedes comenzar a crear tus propias funciones o clases para extraer datos y realizar acciones en la mayoría de los sitios web.
Si tienes alguna pregunta sobre el código desarrollado, accede al repositorio de GitHub para más información.
¡Éxito!
Revelo Content Network da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.