¿Sabes qué es la Bioinformática?


¡Hola! En este artículo vamos a hablar de una ciencia que se ha ido expandiendo mucho en los últimos años: la Bioinformática.
La Bioinformática es una ciencia inter y multidisciplinaria que fusiona no solo la biología y las tecnologías de la información, sino también la Estadística, las Matemáticas, la Física, la Química, la Ingeniería, la Medicina, la Agricultura, entre otras áreas de la ciencia y la tecnología para organizar, analizar, interpretar y procesar datos biológicos a través de diferentes herramientas y tecnologías (figura 1).
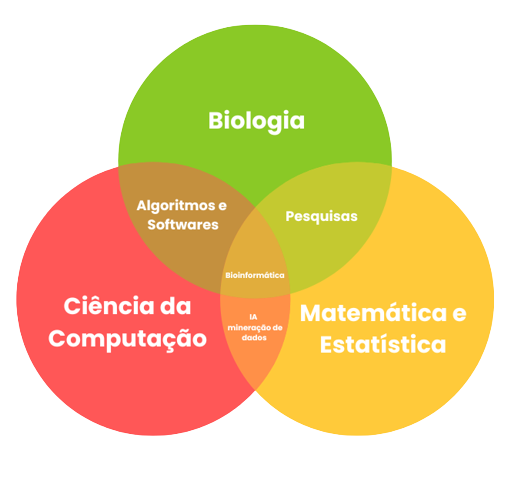
Griffiths et al (2008) definen la Bioinformática como un sistema de información computacional y métodos analíticos aplicados a problemas biológicos. Thampi (2009), agrega que la Bioinformática es un área que se encuentra en la encrucijada de la ciencia experimental y teórica, y no se trata sólo de modelado de datos o “minería”, se trata de comprender el mundo molecular que alimenta la vida desde perspectivas evolutivas.

Una breve historia
En 1953, un artículo de James Watson y Francis Crick, publicado en la revista Nature, cambió la historia de la ciencia mundial. Watson y Crick describieron la estructura de la molécula de ADN como una doble hélice enrollada, pero su descubrimiento atrajo poca atención por parte de la comunidad científica en ese momento. Pero no fue hasta 1957 que el estudio ganó notoriedad, cuando los científicos demostraron que el ADN se replicaba, algo que ya habían predicho en 1953.
Este momento desencadenó una revolución en las investigaciones científicas vinculadas a las ciencias de la vida y fueron claves para el nacimiento de la bioinformática, debido a las herramientas que los científicos utilizaron en sus descubrimientos.
Fue a principios de la década de 1970 cuando el término bioinformática fue utilizado originalmente por los biólogos Paulien Hogeweg y Ben Hesper para definir “El estudio de los procesos informáticos en sistemas bióticos”. Sin embargo, la fisicoquímica norteamericana Margaret Dayhoff fue conocida como la “madre de la bioinformática”, por ser pionera en la aplicación de métodos matemáticos y computacionales para determinar secuencias peptídicas.
En 1965, el Dr. Dayhoff participó en la creación del “Atlas de Secuencia y Estructura de Proteínas”, la primera base de datos pública computarizada de secuencias de proteínas.
Funciones típicas
Según Lorenzoni (2019), son:
- Desarrollo de nuevos algoritmos y estadísticas;
- Análisis e interpretación de diversos tipos de datos biológicos;
- Desarrollo e implementación de herramientas que permitan el acceso y gestión eficiente de diferentes tipos de información.
- Análisis de secuencias que incluye alineación de secuencias, búsqueda en bases de datos, descubrimiento de motivos y patrones, descubrimiento de genes y promotores, reconstrucción de relaciones evolutivas y ensamblaje y comparación de genomas.
- Análisis estructurales que incluyen análisis, comparación, clasificación y predicción de proteínas y estructuras de ácidos nucleicos.
- Análisis funcional que incluye perfiles de expresión génica, predicción de interacción proteína-proteína, predicción de localización subcelular, reconstrucción y simulación de rutas metabólicas.
Herramientas
Existen numerosos proyectos genómicos cuyos datos generados están disponibles en línea de forma gratuita. Podemos destacar tres bases de datos que se actualizan diariamente:
- NCBI (National Center for Biotechnology Information), uno de los mejores repositorios de secuencias de ADN y ARN, ubicado en Estados Unidos.
- KEGG (Kyoto Encyclopedia of Genes and Genomes) es una enciclopedia japonesa con diferentes repositorios de información biológica además de ser una herramienta de mapeo metabólico.
- UniProt (Universal Protein Resource), una base de datos de proteínas suiza, que proporciona excelentes herramientas para anotar secuencias de proteínas y estructuras tridimensionales.
Además de las bases de datos mencionadas, existen muchas otras herramientas utilizadas por los bioinformáticos, como los lenguajes de programación. Python, R, Shell Script, Julia y Rust se utilizan comúnmente para crear scripts y herramientas bioinformáticas.
As linguagens Python e R são preferidas em análises biológicas por serem simples e de fácil entendimento e aprendizado, além de oferecerem vantagens nas análises de dados.
Python es un lenguaje que cuenta con varias herramientas para biología molecular, soporta varios archivos comúnmente utilizados en bioinformática, además de estar integrado con una base de datos para secuencias moleculares. BioSQL.
R, a su vez, ofrece herramientas estadísticas, al ser una herramienta destinada a la ciencia de datos.
Tanto Python como R ofrecen paquetes especializados para análisis y gestión de datos. Tenemos Biopython, XGBoost, Sklearn, Pandas y Flask para Python. Mientras que para R tenemos Bioconductor.
Objetivos
Actualmente, la Bioinformática tiene como objetivo resolver cuestiones y problemas biológicos utilizando modelos computacionales, con el fin de optimizar el trabajo de análisis e interpretación de datos de moléculas biológicas, donde este proceso se denomina biología computacional.
Ya que al entender cómo funciona cierto ADN es posible prevenir y combatir enfermedades con medicamentos y tratamientos genéticos más eficientes, combatir el cambio climático desarrollando y aplicando métodos sostenibles, favorecer el desarrollo de la agricultura de forma sostenible y segura con cultivos más resistentes a plagas, al cambio climático y libres de pesticidas, por ejemplo, promoviendo así una mejor calidad de vida para todos los seres vivos.
Bioinformática en Brasil
A finales de 1999, los científicos João Meidanis y João Carlos Setúbal, ambos vinculados al Centro de Computación de la UNICAMP (Universidad de Campinas), utilizaron un software para realizar la secuenciación completa del ADN de una bacteria que causaba daños a los cultivos de cítricos, la Xylella. fastidiosa, considerada una plaga para las plantaciones de naranjos porque causa una enfermedad llamada clorosis variegada de los cítricos (CVC), popularmente llamada amarillamiento.
Según el artículo, el genoma secuenciado consta de un cromosoma circular de 2.679.305 pares de bases (pb) rico en nucleótidos GC.
Según Tavares (2022), el proyecto Xylella costó 13 millones de dólares y fue adquirido en el consorcio ONSA (Organization for Nucleotide Sequencing and Analysis – The Virtual Genomics Institute). Este consorcio integró centros de investigación en diferentes proyectos de secuenciación de ADN a gran escala, haciendo que el ensamblaje del genoma de Xyllela allane el camino para el éxito en el ensamblaje de otros genomas, como el de Xanthomonas citri, Xanthomonas campestris, Lifsonia xyli y una cepa de Xyllela. que ataca a la uva, convirtiendo a Brasil en una referencia en el ensamblaje de genomas de organismos relacionados con la agricultura.
Según Tavares (2022), el país también se destacó en la investigación del cáncer al estudiar genes relacionados con distintos tipos de la enfermedad y tumores malignos.

Referencias Bibliográficas
- Welch, L. et al. Bioinformatics Curriculum Guidelines: Toward a Definition of Core Competencies. PLOS Computational Biology. 2014.
- Bioinformata: 6 dicas para trabalhar com bioinformática, Dezordi, Filipe, disponível em<https://blog.varsomics.com/bioinformata-profissao/#:~:text=6.-,Qual%20o%20salário%20de%20um%20bioinformata%3F,como%20baixo%20e%20alto%2C%20respectivamente>
- THAMPI, S. M. Introduction to Bioinformatics.arXiv preprint arXiv. ComputationalEngineering, Financeand Science, 2009.
- GRIFFITHS, A. J. F.; WESSLER, S. R.; LEWONTIN, R. C.; CARROLL, S. B. Introdução a Genética. 9ed. Guanabara Koogan, 2008.
- Mulder NJ, Adebiyi E, Adebiyi M, et al. Development of Bioinformatics Infrastructure for Genomics Research. Glob Heart. 2017;12(2):91-98. doi:10.1016/j.gheart.2017.01.005
- Oliver GR, Hart SN, Klee EW. Bioinformatics for clinical next generation sequencing. Clin Chem. 2015;61(1):124-135. doi:10.1373/clinchem.2014.224360
- Bioinformática: união entre ciência e tecnologia.Safady, Nágela G. disponível em<https://blog.varsomics.com/bioinformatica/#:~:text=tridimensionais%20das%20proteínas.-,Quando%20surgiu%20a%20bioinformática%3F,como%20a%20mãe%20da%20bioinformática.>
- Bioinformática e Biologia Computacional, Biotecnologia, Ciência, Produção Científica, Profissional, V.2 (2017), Douglas Souza Vieira
- Bioinformática no Brasil: uma história recente, 2022. Tavares, Thayana, disponível em <https://blog.neoprospecta.com/bioinformatica-no-brasil/ >
- Bioinformática - Parte II: Fundamentos e Aplicações, 2019, Lorenzoni, Rodrigo Monte, disponível <https://www.laborgene.com.br/fundamentos-da-bioinformatica/>
Listopro Community da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.