Reconocimiento y generación de voz con Whisper y gTTS y Python


La Inteligencia Artificial (AI) se sigue expandiendo por todos los ámbitos de nuestra vida. Principalmente este 2023, donde los modelos generativos han tomado relevancia. No solo se han popularizados los chats inteligentes como ChatGPT, o los generadores de código como GitHub Copilot, o los modelos que permiten generar imágenes realistas como DALL·E 3, también hay novedades en el ámbito del reconocimiento y generación de voz.
En este tutorial revisaremos dos tipos de herramientas para trabajar con audio en Python:
- Whisper, una biblioteca que realiza un reconocimiento de voz automático, dado un audio este lo transcribe a texto, fue creada por OpenAI. Admite la posibilidad de reconocer voces para una amplia gama de idiomas.
- Y gTTS (Google Text-to-Speech), una biblioteca que transforma un texto a audio, usando la interfaz de Google Translate.
Comenzaremos explicando cómo ambas se instalan, entonces, varios ejemplos en Python + Whisper + gTTS serán expuestos y explicados.

Instalación
Ambas bibliotecas se pueden instalar con pip, el gestor de paquetes de Python.
pip install gTTS
pip install git+https://github.com/openai/whisper.git
En caso de error en la instalación, es probable que le falte algún prerrequisito. Para esto le recomendamos visitar los repositorios de cada biblioteca en donde se explican las soluciones a ese tipo de problemas:
Para verificar que se han instalado correctamente, puede comprobarlo – en Linux – con el comando which, que devuelve la ruta donde se encuentra el ejecutable.
which gtts-cli
which whisper
Un ejemplo preliminar (terminal)
En este ejemplo comenzaremos usando ambas bibliotecas en la terminal. En la siguiente sección veremos cómo usarlas con Python.
Entonces, primero vamos a crear un audio desde un texto usando gTTs:
gtts-cli "¡Hola, Listopro!" --lang es --output saludos.mp3Ahora con el audio generado, saludos.mp3, lo transcribimos con Whisper:
>> whisper saludos.mp3 --language Spanish
[00:00.000 --> 00:01.560] Hola. Listo Pro.Con esto ya tenemos el ciclo completo: texto a audio, y, audio a texto.
Ten en cuenta que Whister también permite aplicar una traducción directa al inglés:
>> whisper saludos.mp3 --language Spanish --task translate
[00:00.000 --> 00:02.000] Hello. ListoPro.
(En la actual versión de Whisper, la traducción solo es posible hacia el inglés).
Le recomiendo revisar las restantes posibilidades que ofrecen cada biblioteca con la bandera --help :
gtts-cli --help
whisper --help
Usando Whisper + Python
Una vez ya estás seguro de que está instalado Whisper en tu computador, procedemos a hacer una prueba, para esto creamos un fichero de nombre test_whisper.py con el siguiente código:
import whisper
model = whisper.load_model("base")
audio = whisper.load_audio("saludos.mp3")
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
print(result.text)
Ahora pasamos a explicada cada línea:
import whisper
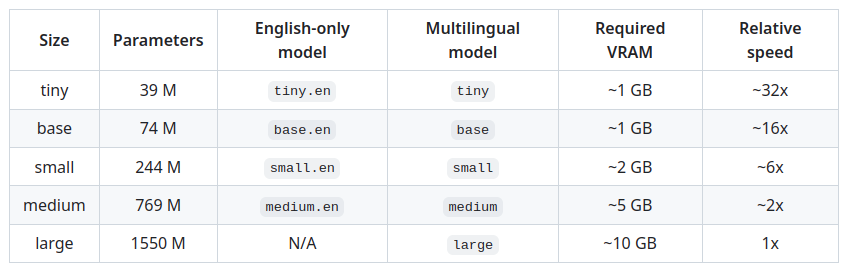
model = whisper.load_model("base")Aquí se carga la líbreria Whispter y después se carga el modelo preentrenado que se usará para poder transcribir. Hay multiples opciones, en este ejemplo usaremos «base», pero podrían usarse modelos más pequeños o grandes, que nos devolverían los resultados más rápido o lento. De esta elección la calidad del resultado puede verse afectada. En cualquier caso, depende del audio en cuestión. Le sugerimos revisar la tabla a continuación:
audio = whisper.load_audio("saludos.mp3")
audio = whisper.pad_or_trim(audio)
En la primera línea se carga el audio saludos.mp3 y, en la siguiente, la función pad_or_trim rellena y recorta el audio en espacios de 30 segundos. Esto para un mejor funcionamiento del decodificador (ya lo veremos a continuación).
mel = whisper.log_mel_spectrogram(audio).to(model.device)Un log-Mel espectrograma es una representación de audio que combina características de espectrogramas y escala logarítmica de Mel para capturar información relevante del sonido. En otras palabras, nos permite detectar los patrones de audio que produce la voz: entonación, ritmo, velocidad, todas ellas informaciones necesarias para nutrir al modelo y alcanzar una mejor transcripción.
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
Aquí, gracias al log-Mel espectrograma y al modelo de Whisper, descubrimos en qué idioma se está hablando en el audio. De la siguiente forma: el modelo le asigna una probabilidad a cada idioma y muestra por pantalla la que obtenga la mayor, en este caso fue «es» (Español).
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
print(result.text)
La función DecodingOptionses necesaria en caso que quisieras añadir atributos específicos para la transcripción (decodificación). En este caso, como no tenemos nada especial, simplemente creamos un objeto estándar y lo asignamos a la variable options. Después viene lo importante: la transcripción se realiza con la función decode, dando como argumento el modelo de Whisper, la variable mel (del espectrograma) y las opciones de decodificación. Finalmente, podemos mostrar en pantalla la transcripción propuesta del modelo para el fichero saludos.mp3:
Detected language: es
Hola. Listo, pro.
Usando gTTS + Python
El uso de gTTS con Python es muy simple, pues su API es minimalista. Veamos un ejemplo:
from gtts import gTTS
tts = gTTS('Hola, ¿qué tal te ha parecido este tutorial para Listopro?', lang='es')
tts.save('saludos.mp3')
Lo primero es cargar el módulo gttsde la biblioteca de gTTS. Luego se crea el objeto tts para la generación del audio, el primer argumento es el texto y el segundo el idioma del texto. En este caso es español. Finalmente, se guarda el objeto ttsdándole un nombre al fichero de audio, en este caso saludos.mp3.
Integración: Whisper + gTTS + Python
La integración se vuelve obvia. Primero creamos un audio en español con gTTS y luego lo transcribimos con Whisper. ¡Veámoslo!
Primero creamos el audio en un fichero de nombre integracion.py:
from gtts import gTTS
tts = gTTS('Hola, este es un ejemplo que necesito transcribir para Whisper', lang='es')
tts.save('integracion.mp3')Ahora, desde el fichero el mismo fichero integracion.py procedemos a añadir la parte de Whisper concerniente a la transcripción:
import whisper
model = whisper.load_model("base")
audio = whisper.load_audio("integracion.mp3")
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
print(f"Detectando el idioma: {max(probs, key=probs.get)}")
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
print(result.text)Y solo nos queda ejecutar:
> python3 test_whisper.py
Detectando el idioma: es
Hola, este es un ejemplo que necesito transcribir para Guisper.Como podemos apreciar: se ha equivocado en el nombre de «Whisper» generando «Güisper», lo cual es correcto dado que el «Wh» no es parte del español, por tanto, lo cambia a «Gü». ¡Bastante perspicaz!

Conclusión
Los modelos generativos son de gran utilidad para labores como transcrición y generación de voz. Aun cuando la máxima calidad del modelo se alcanza con voces en inglés (ya que fue entrenado con más datos en dicho idioma), los resultados en español son aceptables. Bastante aceptables. Y se espera que seguirán aumentando su calidad con el paso del tiempo. Ahora ya son mejores que varias herramientas de, no hace muchos años que, por un lado, transcribían mal, y por otro, generaban una voz robótica que era claramente falsa.
Como experiencia personal puede decir que al probar Whisper con un audio de 30 minutos de duración (en inglés), los resultados fueron muy buenos (aunque, por supuesto, puede tardar varios minutos dependiendo del computador donde lo ejecutes). El resultado se puede ver en esta entrevista, realizada a un científico de la computación.
Será normal que estas herramientas sigan evolucionando e integrándose con otras, como podría ser, la traducción automática de voz de un idioma a otro, o los modelos que realizan cambio a un video (por ejemplo, el movimiento de los labios). Esto último es algo que está comenzando a generar bastante interés en la comunidad. Acaso, ¿llegará el día que desconocer otro idioma dejará de ser un problema gracias a los modelos generativos de voz?
Seguir aprendiendo
Whisper
Para continuar el aprendizaje de Whisper les recomiendo los siguientes recursos:
- Un muy buen tutorial de Whisper + Python para transcribir un video desde YouTube: https://towardsdatascience.com/speech-to-text-with-openais-whisper-53d5cea9005e
- Una introducción en video de Whisper, «Tutorial- cómo usar Whisper desde cero» de Beatriz Molina. Enlace: https://youtu.be/89h9LIgI0gQ?si=hth4PUhT7IJdNojD
- Para una introducción teórica de Whisper, le recomiendo aproximarse a su artículo: https://cdn.openai.com/papers/whisper.pdf
gTTS
En el caso de gTTS le recomiendo leer los tutoriales de a continuación:
- Un buen ejemplo de usar gTTS con Python añadiendo una interfaz gráfica: https://python.plainenglish.io/text-to-speech-conversion-using-python-with-gtts-eb4aa0f6dfb7
- Otro buen tutorial, y en la misma línea que el anterior, es el siguiente: https://levelup.gitconnected.com/make-your-python-program-speak-310766534fbf
Referencias
- La documentación de gTTS: https://gtts.readthedocs.io/en/latest/
- Ejemplos de Whisper en Python: https://colab.research.google.com/github/openai/whisper/blob/master/notebooks/LibriSpeech.ipynb
Listopro Community da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.