Python para automatizar hojas de Excel: el tutorial que necesitas

Python se ha vuelto cada vez más popular entre los entusiastas de la ciencia de datos y los desarrolladores de software. Según el índice Tiobe (2022), Python es el primer lenguaje de programación más popular del mundo. Una de las razones de esta clasificación es que el lenguaje es compatible con las áreas más innovadoras del desarrollo de software, como la IA, el aprendizaje automático y el aprendizaje profundo.
Además, Python es un lenguaje fácil de usar. Los principiantes con pocos conocimientos de programación pueden aprender fácilmente la sintaxis de Python y usarla para crear programas simples.
Como el lenguaje tiene varias bibliotecas, paquetes útiles y funciones listas para usar para la automatización que facilitan mucho las pruebas, ¿por qué no usar Python para trabajar con Excel y crear automatizaciones?
Python y Excel
Excel es una de las herramientas de datos más utilizadas en las empresas. Trabajar con datos en Python tiene varias ventajas, por lo que encontrar una manera de trabajar con Excel usando código es clave. Podemos decir que ya existe una gran herramienta para usar Excel con Python llamada Pandas.
En este artículo, usaremos el paquete Pandas para realizar algunas manipulaciones básicas y crear tablas dinámicas como informes automatizados basados en un archivo de datos de Excel.
Prerrequisitos
Para seguir este tutorial, necesitarás:
- Conocimientos básicos del lenguaje de programación Python.
- Conocimientos en Excel.
Paso 1: analizar un conjunto de datos en Excel
En este tutorial, usaremos un archivo Excel creado por Frank Andrade como exemplo. Imaginemos una situación en la que usas un documento como herramienta en tu trabajo para realizar reportes mensuales a través de tablas dinámicas de ventas. Puedes descargar el archivo aquí.
Debido a que esta hoja de trabajo contiene los datos con los que trabajarás, es importante que la revises para familiarizarte con tu propósito.
1.1 Importar las bibliotecas y preparar las condiciones
Necesitaremos importar las bibliotecas de Python a nuestro banco de trabajo para crear las acciones en Excel como la tabla dinámica. Pero primero, debes instalarlos a través de tu terminal:
pip install pandas
pip install openpyxl
Pandas es un paquete de Python que proporciona estructuras de datos rápidas, flexibles y expresivas, diseñadas para que trabajar con datos sea fácil e intuitivo, Siendo una de las bibliotecas más utilizadas para crear esta integración entre Python y Excel, al tratar la hoja de cálculo como una base de datos.
Openpyxl trata a Excel como una hoja de cálculo, editando como un VBA y manteniendo la estructura original de los archivos. Con este módulo, es posible realizar cálculos de Excel y crear gráficos y tablas. Recordemos que usaremos la plataforma Jupyter para ejecutar el código, por lo si deseas usar el mismo entorno, sugiero seguir la guía de instalación aquí.
Con tu entorno abierto, crea un archivo y ejecuta los siguientes comandos para importar las bibliotecas:
import pandas as pd
import openpyxl
from openpyxl import load_workbook
from openpyxl.styles import Font
from openpyxl.chart import BarChart, Reference
import string
Para leer nuestro archivo ““supermarket_sales.xlsx”, usaremos la función pd.read_excel(), como se demuestra en el código a continuación:
table = pd.read_excel(“supermarket_sales.xlsx”)
Atención: este código debe estar en la misma carpeta que el archivo. Si es necesario, indica la ruta en el nombre del archivo. Ejemplo:
”C:\Users\Public\supermarket_sales.xlsx”.
El resultado será la presentación de la tabla dentro del archivo:

Paso 2: crear nuestra tabla dinámica a partir de los datos de entrada
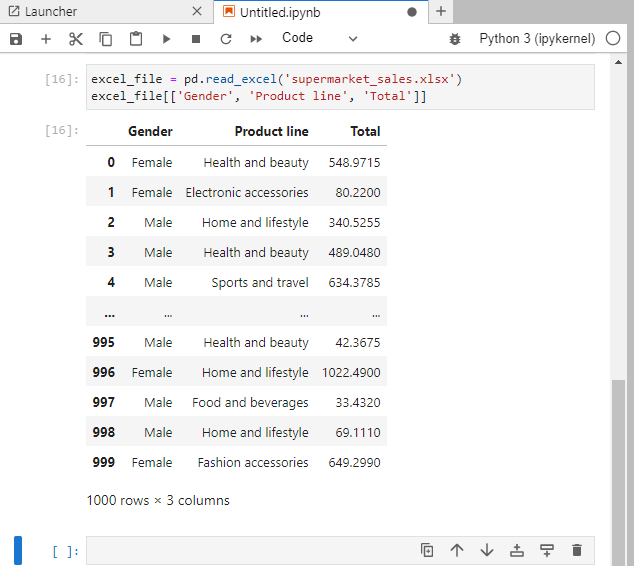
El archivo tiene muchas columnas, pero para simplificar el proceso, solo usaremos las columnas Género, Línea de producto y Total para el informe que crearemos.
excel_file = pd.read_excel('supermarket_sales.xlsx')
excel_file[['Gender', 'Product line', 'Total']]
Para crear nuestra Tabla Dinámica, usaremos la función .pivot_table() para mostrar, por ejemplo, el dinero total gastado por hombres y mujeres en las diferentes líneas de productos.
Con eso en mente, ejecutaremos este grupo de códigos:
report_table = excel_file.pivot_table(index='Gender',
columns='Product line',
values='Total',
aggfunc='sum').round(0)
display(report_table)
Si todo salió bien, quedaría como lo que se muestra a continuación:
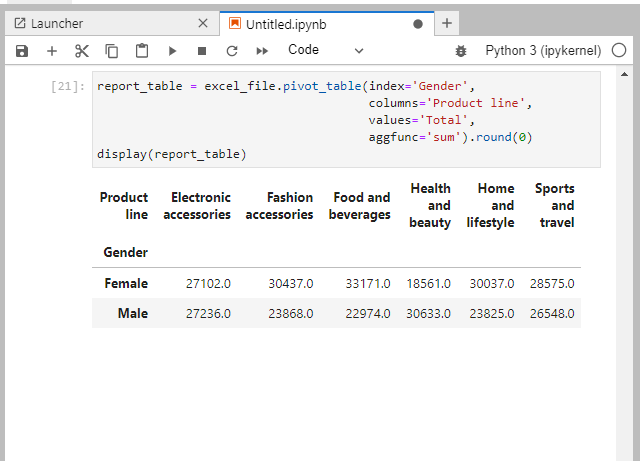
La función aggfun = 'sum' do pivot_table es usada para calcular la suma de los puntos en las columnas agrupadas. La función .round(0) sirve para retorno nulo.
2.1 Exportar nuestra tabla dinámica a un archivo en Excel
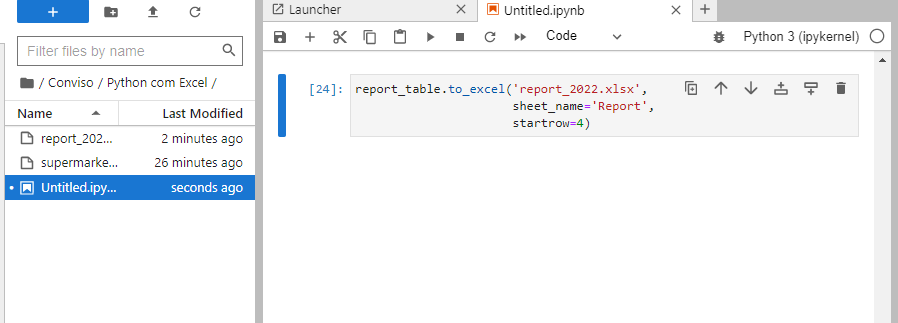
La función _to_excel() se usará para exportar nuestro archivo generado en Python. En ese método, indicaremos el nombre del archivo Excel de salida, siendo “report_2022.xlsx” el nombre que elegiremos en esta ocasión.
Así, es posible especificar el nombre de la hoja de cálculo que deseamos crear y en cuál celda se grabará la tabla dinámica.
report_table.to_excel('report_2022.xlsx',
sheet_name='Report',
startrow=4)
Después de ejecutar esta secuencia, al mirar la carpeta encontrarás un nuevo archivo de Excel creado a partir del método to_excel():
Paso 3: utilizar la biblioteca Openpyxl para generar informes y referencias
Hasta ahora hemos entendido un poco sobre el uso de la biblioteca Pandas. En esta sección usaremos funciones de la biblioteca Openpyxl como load_workbook, la cual se encargará de cargar el contenido del archivo XLSX (la carpeta de trabajo) en la memoria y la función .save() para guardarla tras la edición.
3.1 Crear referencia de filas y columnas
Entonces, para automatizar el informe, necesitamos identificar las columnas y filas mínimas y máximas que estarán activas para garantizar que, después de agregar más datos a la hoja de trabajo, el código seguirá funcionando.
Luego cargamos el libro de trabajo usando el load_workbook() y ubicamos la hoja de trabajo con la que queremos trabajar a través del wb[‘name_of_sheet’]. Tras lo anterior, ingresamos las celdas activas con .active.
wb = load_workbook('report_2022.xlsx')
sheet = wb['Report']
# Referência para a planilha original
min_column = wb.active.min_column
max_column = wb.active.max_column
min_row = wb.active.min_row
max_row = wb.active.max_row
Paso 4: automatizar el informe en Excel con Python
Ahora que tenemos un informe presentado a través de una tabla dinámica, la siguiente parte (y más importante) es automatizar su creación. Entonces, la próxima vez que desees hacer ese informe, simplemente escribe el nombre del archivo y ejecútalo con el código de Python.
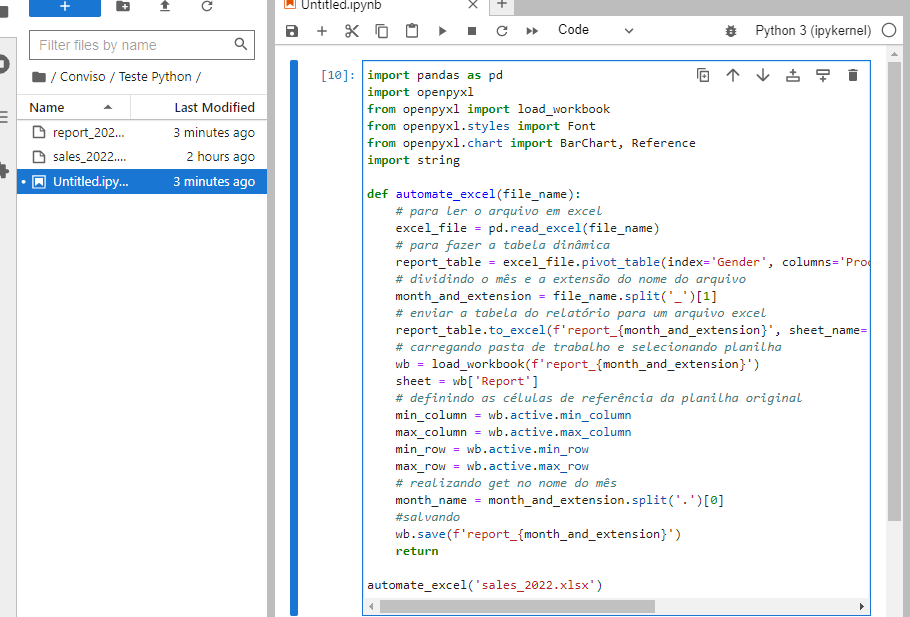
En esta parte, vamos a componer todo el código usando una función para simplificar la automatización de nuestro informe. Imaginemos que el archivo original que descargamos tiene el nombre “sales_2022.xlsx” en lugar de “supermarket_sales.xlsx”.
Con eso podemos aplicar la fórmula al informe escribiendo lo siguiente:
import pandas as pd
import openpyxl
from openpyxl import load_workbook
from openpyxl.styles import Font
from openpyxl.chart import BarChart, Reference
import string
def automate_excel(file_name):
# para leer el archivo en Excel
excel_file = pd.read_excel(file_name)
# para hacer la Tabla Dinámica
report_table = excel_file.pivot_table(index='Gender', columns='Product line', values='Total', aggfunc='sum').round(0)
# dividir el mes y la extensión del nombre del archivo
month_and_extension = file_name.split('_')[1]
# enviar la tabla del informe para un archivo Excel
report_table.to_excel(f'report_{month_and_extension}', sheet_name='Report', startrow=4)
# cargar la carpeta de trabajo y selecionar hoja de cálculo
wb = load_workbook(f'report_{month_and_extension}')
sheet = wb['Report']
# definir las celdas de referencia de la hoja de cálculo original
min_column = wb.active.min_column
max_column = wb.active.max_column
min_row = wb.active.min_row
max_row = wb.active.max_row
# realizar get en el nombre del mes
month_name = month_and_extension.split('.')[0]
#guardar
wb.save(f'report_{month_and_extension}')
return
automate_excel('sales_2022.xlsx')
Después de ejecutar este código, verás un archivo de Excel llamado “report_2022.xlsx” en la misma carpeta donde se encuentra el script de Python:
Para aplicar la función a varios archivos, basta con aplicar la fórmula uno por uno, por ejemplo:
automate_excel('sales_january.xlsx')
automate_excel('sales_february.xlsx')
automate_excel('sales_march.xlsx')
También puedes seleccionar cuáles actividades deseas agregar cada vez que uses la función en una hoja de trabajo, pudiendo formatear la tabla, crear gráficos, nuevas tablas y mucho más. En este sitio, encontrarás una lista de estilos disponibles.
Eso es solo el comienzo
Espero que después de leer este artículo uses los conceptos básicos de la automatización de archivos de Excel a través de secuencias de comandos de Python.
Recuerda que es posible hacer mucho más que crear tablas dinámicas a través de estas interacciones. Esto fue solo un ejemplo para facilitar el aprendizaje.
La biblioteca de Pandas puede realizar varias operaciones en tu base de datos, como análisis y manipulaciones complejas. Dependiendo de tus necesidades y experiencia, es posible ir más allá de lo que puedes lograr solo con Excel. Uno de los principales beneficios de estas bibliotecas en Python es la automatización y el procesamiento de archivos de Excel a través de scripts, integrando los resultados en tu flujo de trabajo de datos de forma automatizada.
Aprende más sobre el tema
Aquí hay algunas referencias importantes que pueden ayudarlo a profundizar en el universo de Python y Excel:
- A Simple Guide to Automate Your Excel Reporting with Python
- Automating Excel Sheet in Python
- Using Pandas in Excel
Revelo Content Network da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.