Optimizando el desempeño de la Base de Datos SQL: Consejos y técnicas


En un mundo donde los datos se consideran el nuevo oro, es esencial garantizar que las operaciones relacionadas con los datos sean rápidas y eficientes. SQL, al ser un lenguaje estándar para gestionar y consultar datos en bases de datos relacionales, es donde muchas empresas suelen encontrar cuellos de botella en el rendimiento.
En este artículo, cubriré 20 consejos y técnicas esenciales para optimizar el rendimiento de una base de datos SQL.

1. Entendiendo Planos de Ejecución
Antes de poder ajustar tus consultas, debes comprender cómo funcionan. Los planes de ejecución describen la secuencia de pasos utilizados para acceder a los datos. Al analizar estos planes, se pueden identificar cuellos de botella y posibles optimizaciones.
El uso de EXPLAIN es un excelente comienzo:

El estudio de los resultados puede revelar si se utiliza un índice, el orden de unión de las tablas y otras operaciones internas.
2. El poder de la indexación
Los índices son estructuras que pueden acelerar drásticamente las consultas. Imagínese buscar un nombre en un libro de 1000 páginas que no tiene índice; Tendrías que hojear página por página.

Al crear índices apropiados, el servidor puede encontrar rápidamente los registros necesarios. Sin embargo, mantener índices tiene un costo: cada inserción, actualización o eliminación puede requerir una actualización del índice.
3. Evitando el SELECT *
La tentación de usar SELECT * para buscar todos los campos de una tabla es comprensible, especialmente cuando no estás seguro/a de qué columnas son necesarias. Sin embargo, esta práctica puede generar consultas ineficientes, lo que genera una sobrecarga innecesaria en la base de datos. Al recuperar información excesiva, es posible que experimentes retrasos en el tiempo de respuesta y una alta utilización de recursos. Siempre se recomienda especificar solo aquellas columnas imprescindibles para la operación en cuestión.

Al ser prudente acerca de qué columnas buscar, optimizas el rendimiento de la base de datos y reduces el tráfico de datos, beneficiando a la aplicación en su conjunto.
4. Usando JOINs adecuadamente
La capacidad de unir tablas es una de las características más valiosas y poderosas de las bases de datos relacionales. Sin embargo, si se usan mal, los JOIN pueden ser un talón de Aquiles para el rendimiento de las consultas. Al combinar registros de dos o más tablas, es fundamental asegurarse de que las columnas utilizadas en la condición JOIN estén indexadas correctamente, evitando escaneos completos de la tabla.

Además, comprender el propósito de los diferentes tipos de JOINs (INNER, LEFT, RIGHT, etc.) es vital. Optar por el tipo de JOIN más específico para tus necesidades no solo hará que su consulta sea más clara, sino que también ayudará al servidor a procesar menos registros, optimizando el rendimiento general de la consulta.
5. Limitando resultados
Es común querer ver solo un subconjunto de registros. El uso de la cláusula LIMIT puede restringir la cantidad de registros devueltos, ahorrando tiempo y recursos.

6. Consultas parametrizadas
Las consultas parametrizadas son un enfoque que permite a los desarrolladores especificar parámetros en lugar de ingresar valores directamente en las consultas SQL.
Esta práctica aporta una importante capa de seguridad, ya que ayuda a prevenir ataques de inyección SQL, una de las vulnerabilidades más comunes en las aplicaciones web. Además de ser más seguras, estas consultas también ofrecen ventajas de rendimiento. Cuando se utiliza una consulta parametrizada, el servidor puede reconocer y optimizar la estructura de la consulta incluso cuando los valores de los parámetros cambian, lo que puede conducir a tiempos de ejecución más rápidos y consistentes.

7. Normalización de datos
La normalización es un concepto fundamental en el diseño de bases de datos relacionales. Su objetivo es minimizar la duplicación y la dependencia organizando los datos de forma lógica y eficiente. A través de este proceso, los datos se organizan en tablas separadas, basadas en temas o conceptos, y se establecen relaciones entre estas tablas mediante claves.
Esto no solo reduce la redundancia sino que también facilita el mantenimiento, ya que las actualizaciones o cambios en un conjunto de datos no requieren múltiples cambios en diferentes lugares. A largo plazo, contar con una base de datos bien estandarizada facilita las consultas, reduce los errores y garantiza la integridad de los datos.
8. Usando vistas
Las vistas son consultas almacenadas que pueden encapsular lógica compleja o combinaciones de uso frecuente. En lugar de reescribir la misma lógica en varias partes de su aplicación, puede hacer referencia a una vista.

9. Optimizando subconsultas
Las subconsultas son consultas anidadas dentro de otras consultas. Aunque potentes, pueden ser más lentas que alternativas equivalentes como JOINS.
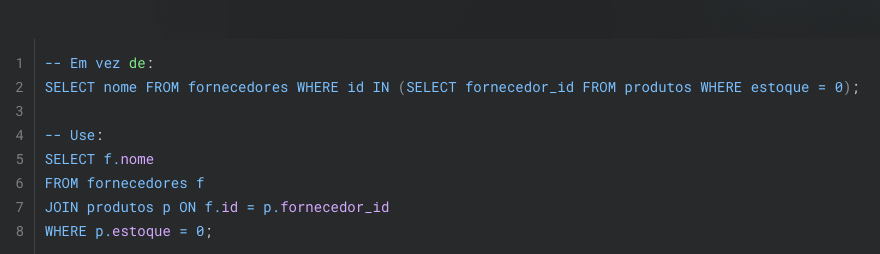
10. Evitando funciones en condiciones WHERE
Aplicar funciones a columnas en cláusulas WHERE puede ser costoso y a menudo impide el uso de índices.

11. Partición de tablas
Las tablas grandes se pueden dividir en partes o particiones más pequeñas, según criterios específicos como rango de fechas, ID o geolocalización. Al dividir las tablas de manera eficiente, se puede mejorar el rendimiento de las consultas, ya que el servidor puede centrarse solo en las particiones relevantes, lo que reduce el volumen de datos a escanear. Este método es especialmente beneficioso para bases de datos con grandes volúmenes de transacciones o datos históricos.
12. Utilizando Caching
El uso de sistemas de almacenamiento en caché como Redis o Memcached ayuda a aliviar la carga de la base de datos. Estas herramientas almacenan en la memoria los datos a los que se accede con frecuencia, lo que da como resultado tiempos de respuesta más rápidos para consultas recurrentes. Al reducir la necesidad de consultar directamente la base de datos para cada pedido, la latencia y el desgaste general del sistema se reducen significativamente.
13. Mantenimiento regular
Mantener una base de datos es similar a mantener un vehículo: ambos requieren atención regular para funcionar de manera óptima. La fragmentación puede ocurrir con el uso continuo, y actividades como optimizar tablas, reconstruir índices y eliminar datos obsoletos son esenciales para mantener la integridad y eficiencia del sistema. Programar y automatizar estas tareas puede garantizar un rendimiento constante a largo plazo.
14. Monitoreo y análisis
El uso de herramientas de monitoreo, como Prometheus o Zabbix, es esencial para mantener la salud de la base de datos. Estas herramientas pueden alertarle sobre consultas ineficientes, bloqueos prolongados o incluso fallas de hardware. Tener información en tiempo real sobre el rendimiento del sistema permite una respuesta rápida a problemas potenciales, lo que garantiza un funcionamiento fluido y reduce el tiempo de inactividad.
15. Réplica de carga
En entornos de alta demanda, la replicación de bases de datos puede ser una solución vital. Tener varias copias de la base de datos no sólo ayuda a distribuir la carga de lectura, sino que también proporciona una capa adicional de redundancia. Los equilibradores de carga como HAProxy o Nginx pueden dirigir el tráfico de forma inteligente entre estas réplicas, garantizando que ninguna instancia se sobrecargue.
16. Considerando NoSQL
Para proyectos que tratan con datos voluminosos y no relacionales, o que requieren alta escalabilidad, las bases de datos NoSQL, como MongoDB, Cassandra o Couchbase, pueden ser la respuesta. Estas soluciones ofrecen flexibilidad en la estructura de datos, distribución horizontal y modelos de coherencia adaptables, lo que las hace ideales para determinadas aplicaciones modernas, como big data o aplicaciones móviles.
17. Backup y recuperación
Si bien esto no es directamente una optimización del rendimiento, es vital asegurarse de tener copias de seguridad periódicas y una estrategia de recuperación. Pueden ocurrir problemas de rendimiento y tener una copia de seguridad reciente puede salvarle la vida.
18. Aprovechando Stored Procedures
Stored Procedures son bloques de comandos SQL que se almacenan en la base de datos y se pueden invocar cuando sea necesario. Como ya están compiladas, pueden ejecutarse más rápido que varias consultas enviadas individualmente.

Con esto, puedes simplemente llamar a BuscarClientesVIP en lugar de reescribir la consulta varias veces.
19. Actualización de versión
A menudo, simplemente mantener actualizado tu SGBD (Sistema de Gestión de Bases de Datos) puede generar mejoras en el rendimiento. Los desarrolladores de estos sistemas publican con frecuencia actualizaciones que abordan problemas de rendimiento, agregan optimizaciones e introducen nuevas funciones que pueden ayudar con operaciones eficientes.
Asegúrate de consultar siempre las notas de la versión y probar la nueva versión en un entorno controlado antes de actualizar el entorno de producción.
20. Evitando Triggers Ineficientes
Triggers son procedimientos automáticos que se ejecutan en respuesta a ciertos eventos en la base de datos, como inserciones, actualizaciones o eliminaciones. Si bien son útiles, pueden ser una fuente oculta de lentitud, especialmente si realizan operaciones complejas o no optimizadas.

Si notas lentitud al insertar en la tabla de ventas, la causa puede ser el trigger. Revisa y optimiza siempre los activadores para asegurarte de que no afecten negativamente al rendimiento.

Conclusión
La optimización de una base de datos SQL es una combinación de arte y ciencia, y requiere una comprensión profunda de las consultas, la estructura de la base de datos y las características específicas del sistema de gestión de bases de datos utilizado.
Espero que con los consejos anteriores esté mejor equipado para enfrentar los desafíos de rendimiento de la base de datos SQL y mejorar significativamente la eficiencia y la capacidad de respuesta de su sistema.
Listopro Community da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.