Introducción a MongoDB Aggregation Operations


Al día de hoy, muchas startups prefieren MongoDB como base de datos por la gran flexibilidad que provee en sus apartados de modelado y/o consulta.
En este artículo, conoceremos más sobre una de las herramientas más prometedoras debido a lo útil que puede ser para procesar documentos de una o múltiples colecciones: las operaciones de agregación.
Cabe aclarar que no tendrás que descargar ni instalar nada, sino que puedes practicar en un playground online presente en este link, así que nos podemos concentrar en lo que realmente importa: ¡Poner en práctica lo aprendido en este artículo!
Pero antes de poner manos a la obra hay que entender un par de conceptos.

¿Qué son las Aggregation Operations?
Son operaciones que permiten aplicar procesos sobre múltiples documentos. Estas pueden hacerse utilizando etapas (Aggregation Pipelines) o funciones de propósito único, pero en este artículo haremos especial énfasis en los Aggregation Pipelines.
¿Qué son las Aggregation Pipelines?
Son secuencias de etapas que permiten efectuar diferentes procesos sobre los documentos de entrada. Cada etapa procesa los documentos y envía el resultado a la etapa siguiente, lo podemos ver con más detalle en el siguiente diagrama:

Como lo indica el diagrama anterior, puede haber n cantidad de etapas.
Al modificar la estructura de los documentos dentro de una etapa, no se modificará nada de la información guardada en la base de datos, a menos de que se usen etapas $merge o $out.
Hay distintos tipos de etapas, cada una con un fin específico como agregar o remover propiedades de los documentos, obtener información de otras colecciones, etc.
En esta ocasión, nos centraremos en las siguientes etapas:
- $match
- $project
Antes de empezar, tendremos que familiarizarnos un poco con la herramienta que usaremos para practicar. Para empezar, demos clic en este link.
Al entrar, debería redirigirlos a una página como la siguiente, con el playground listo para trabajar.
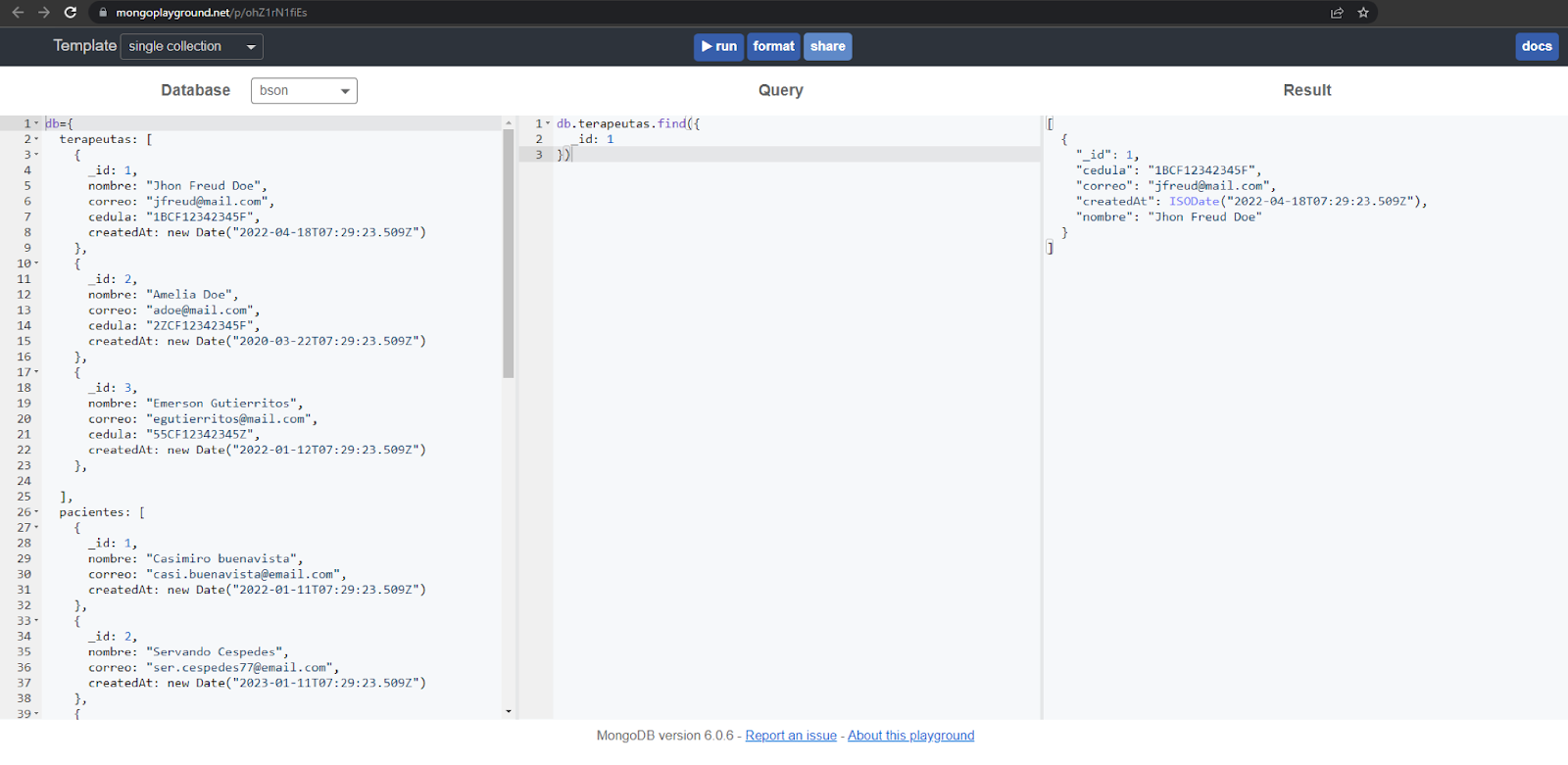
En caso de que la sección Database no tenga contenido, es necesario pegar el siguiente código:
El código anterior es una base de datos para un centro terapéutico ficticio y
servirá de contenido para trabajar con los ejemplos que veremos más adelante.
El sitio en el que trabajaremos es un playground que usa MongoDB Shell (mongosh) para ejecutar comandos, No incluye todo lo que puede hacer mongosh, pero nos permite usar Aggregations sin problemas.
Hablemos un poco de la interfaz, que incluye una sección para el código de la base de datos, el código de las consultas y otra más para mostrar resultados. También incluye unos pequeños botones en la parte superior que nos permiten ejecutar, formatear, compartir y ver la documentación del mismo sitio. Los más importantes son el botón de ejecutar y el de formatear y, para nuestra suerte, es posible accionarlos con atajos o shortcuts, los cuales son Ctrl(Cmd) + Enter para ejecutar y Ctrl(Cmd) + s para formatear.
Una vez comprendida la interfaz, podremos iniciar con nuestras primeras Aggregation pipelines colocando el comando que servirá para contener a cada una de las etapas que ejecutaremos.
Cada etapa es un objeto que contiene una llave que indica su tipo. A su vez, la llave debe contener un objeto con la configuración de la etapa.
Luego de esa pequeña introducción a la estructura de una pipeline, es hora de empezar con los ejemplos de las etapas señaladas con anterioridad.
$match
Es el find de las etapas, con el que puedes agregar condiciones y parámetros para encontrar documentos que las cumplan.
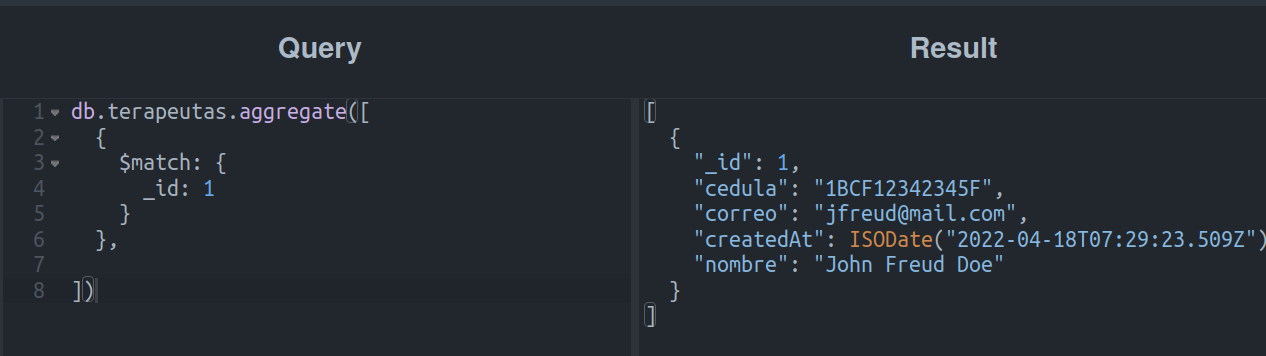
El primer ejemplo y más sencillo de cómo utilizarlo sería el siguiente:
Mediante el ejemplo anterior, podemos filtrar a los terapeutas con el _id “1”. Al ejecutarlo en nuestro playground, podemos ver el siguiente resultado:
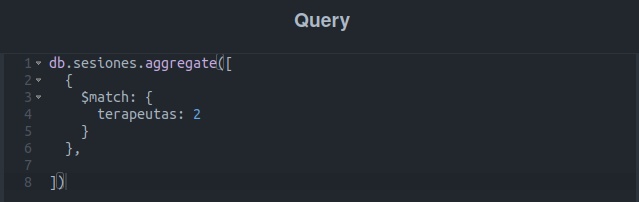
Ahora algo más interesante: buscaremos todas las sesiones en las que estará presente la terapeuta Amelia Doe:
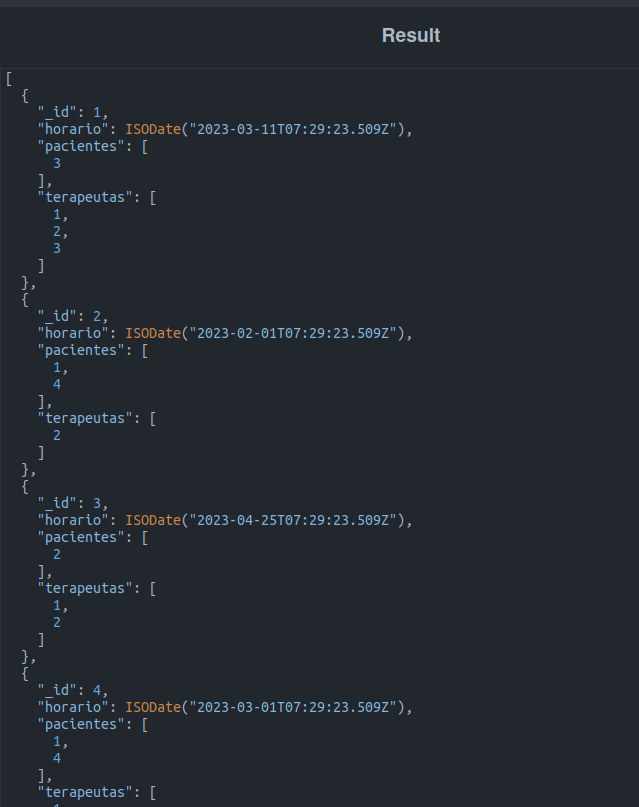
Ahora busquemos las sesiones en donde asistirá más de un paciente:
En esta consulta, hay 3 elementos nuevos. Los conoceremos más a detalle después de ejecutar el comando.
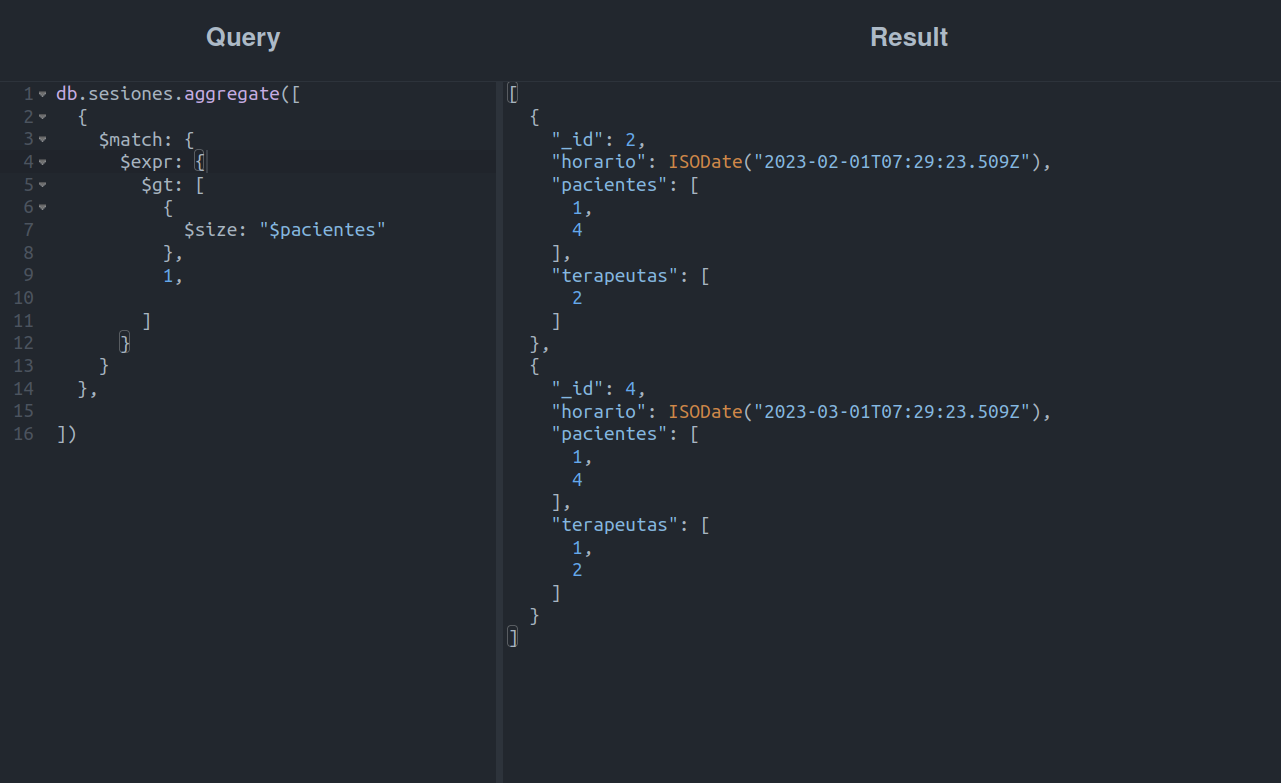
Como podemos notar, ahora tenemos 3 piezas nuevas en el juego:
- $expr, que permite evaluar expresiones con condicionales. Esto nos permite filtrar y descartar todos los documentos que no cumplan con dicha expresión.
- $gt, útil para comparar valores, de forma que retornará un valor verdadero siempre que la expresión A sea mayor que la expresión B.
- $size, nos retorna el conteo de elementos dentro de un arreglo, los cuales pueden ser una literal o un campo de la colección.
Antes de seguir me gustaría mencionar a los ”hermanos” de $gt, son muy útiles y se basan en el mismo principio comparando expresiones A y B:
- $lt, el conocido lower than, menor que o <, para los amigos.
- $lte, similar al anterior, para comparar valores menores o iguales.
- $gte, parecido al que usamos al ejemplo, pero para valores mayores o iguales.
- $eq, para comparar si los valores son idénticos.
- $ne, es verdadero siempre que ambas expresiones sean distintas.
Vayamos al último ejemplo de esta etapa, buscando las sesiones que incluyan a los terapeutas John Freud Doe o Emerson Gutierritos.
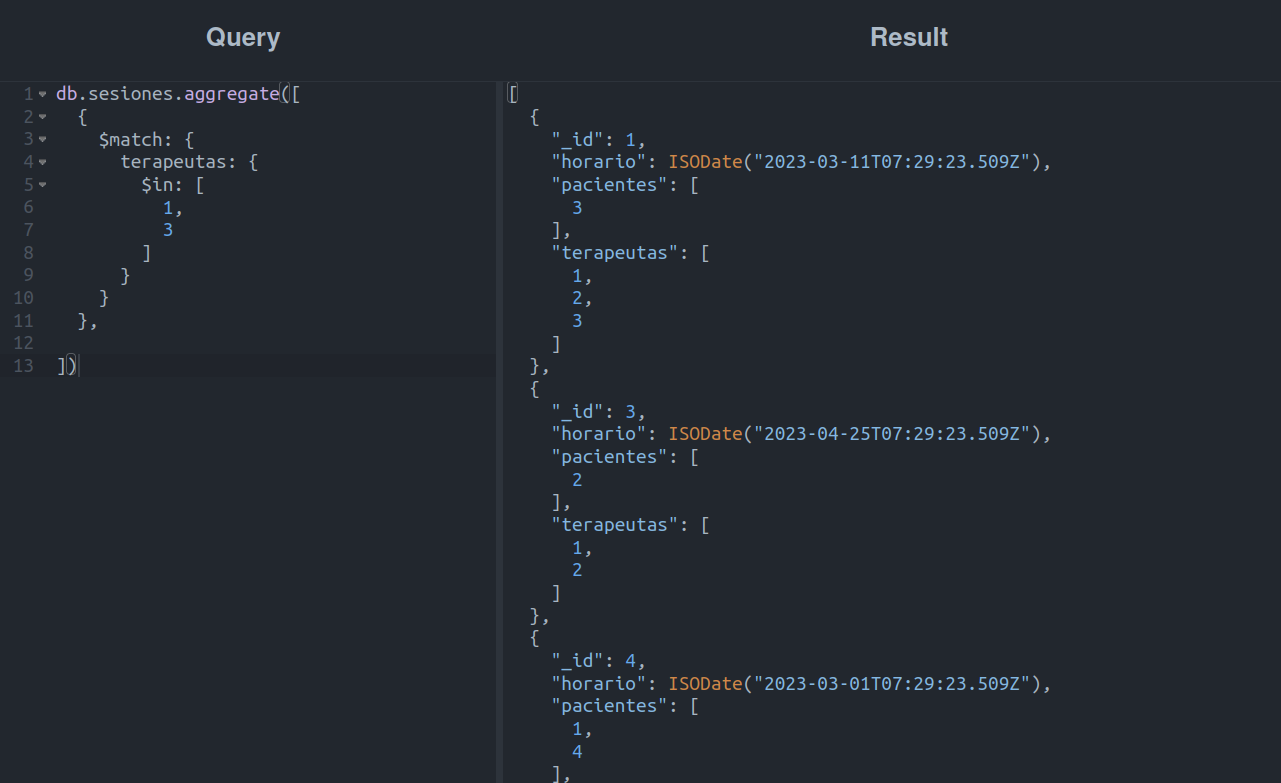
Si tu objetivo es filtrar documentos por parámetro usando un arreglo, $in es el operador que necesitas, pues permite filtrar documentos siempre y cuando el campo especificado contenga o sea igual a uno de los elementos especificados en la lista.
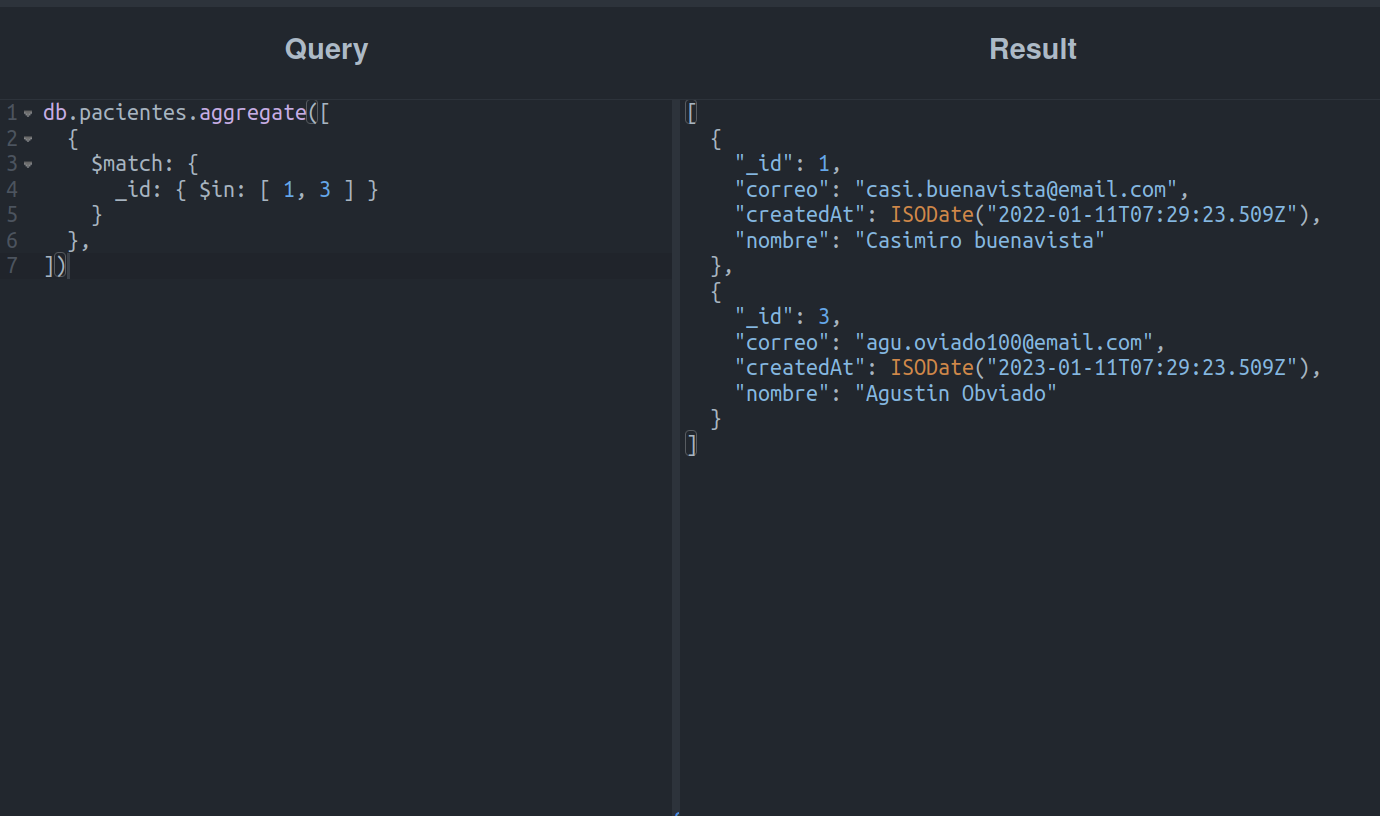
En el ejemplo anterior, se comparó un arreglo con un campo del mismo tipo, pero puede ser usado cuando el contenido del campo es un valor único, por ejemplo:
Esta operación obtendrá a los pacientes siempre y cuando su campo _id esté especificado en la lista del operador $in.
$project
Dentro de esta etapa, podemos modificar los valores de salida, ya sea agregando campos, generándolos con valores calculados o incluso hacer una lista con los campos de los documentos.
Hagamos una consulta que obtenga, únicamente, el nombre y el correo de todos los terapeutas:
Como se puede observar en el código, para indicar qué campos debe contener el resultado, solo hay que escribir el nombre de lo que queremos y asignarle un 1 como valor. En teoría, debería ser así, pues al ejecutarlo podemos notar que tenemos un intruso:
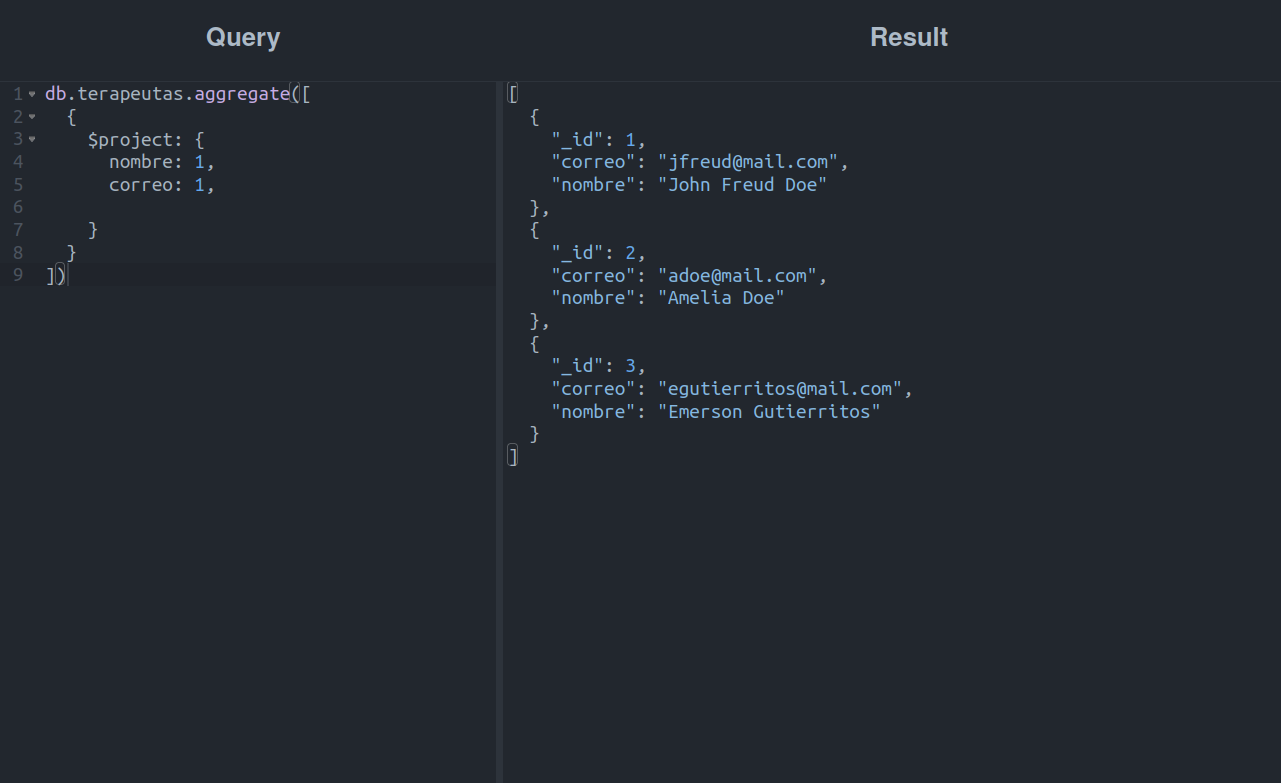
Efectivamente. ¡Se ha colado el _id de los terapeutas!
Esto es un comportamiento normal, ya que a pesar de haber establecido una lista con los campos que deseamos mostrar, la etapa $project siempre retornará el campo _id junto con los campos especificados por nosotros, a menos de que se indique lo contrario:
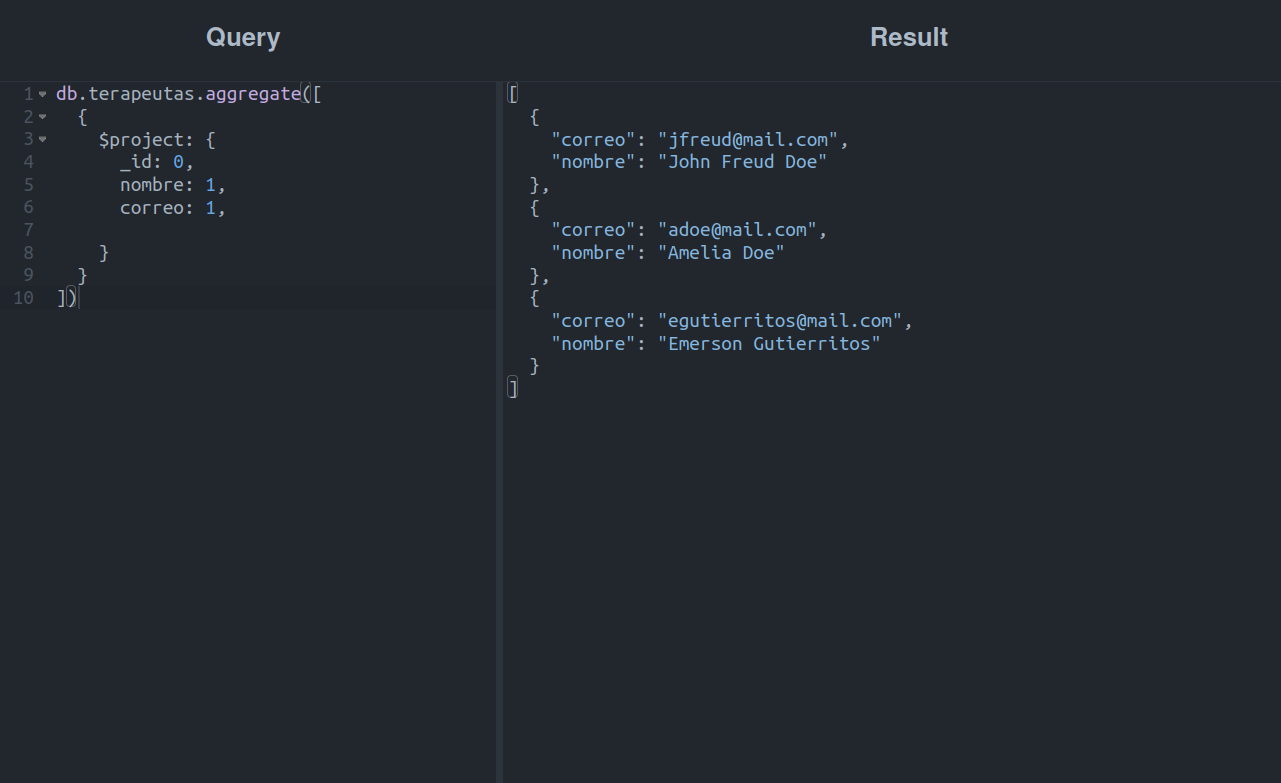
Mucho mejor, ¿no es así?
Bien, ahora intentemos obtener a los terapeutas, pero sin los campos createdAt y _id:
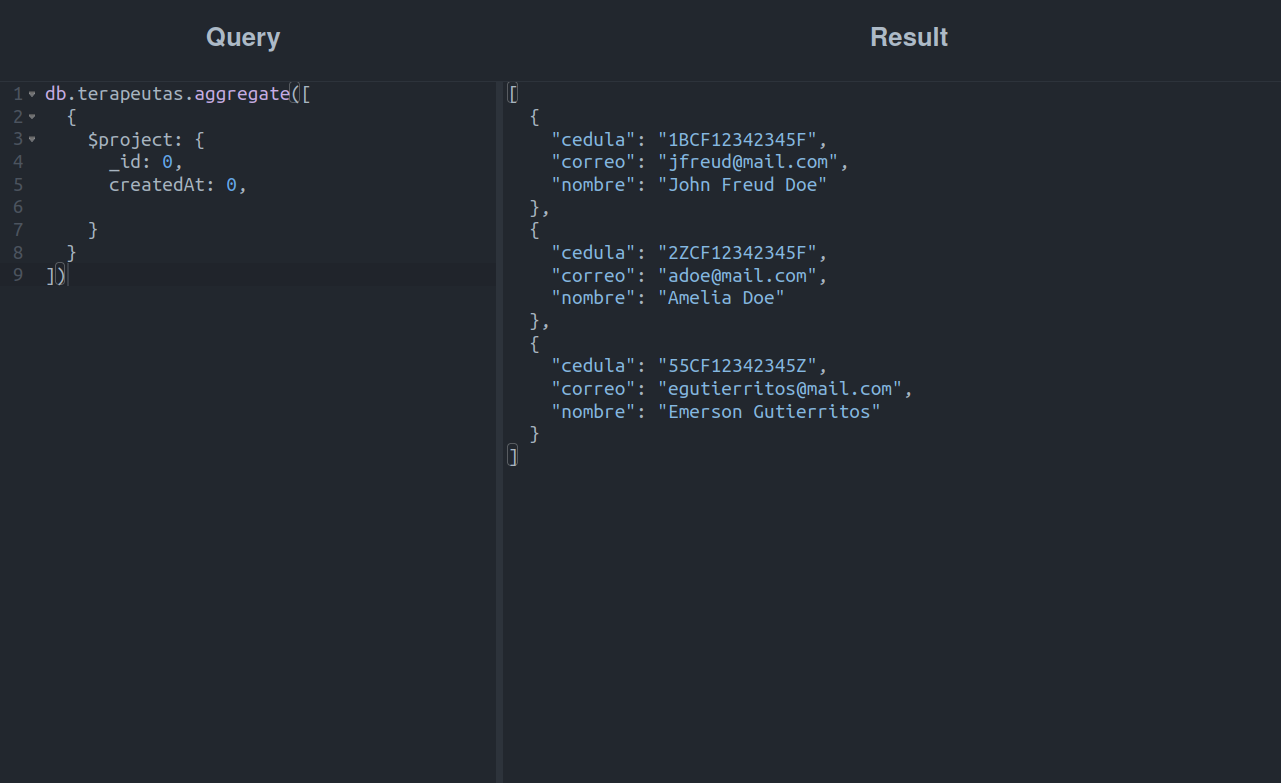
Aquí podemos observar que la etapa $project actuó como una lista y solo mostró los campos que no señalamos con un 0.
Detengámonos por un segundo y pensemos: ¿Será posible incluir un campo y excluir otro en la misma etapa? ¿Qué resultaría si lo intentáramos?
Fácil, pasemos de reflexionar a ser empíricos o, como dicen en mis tierras, “que truene lo que tenga que tronar”.
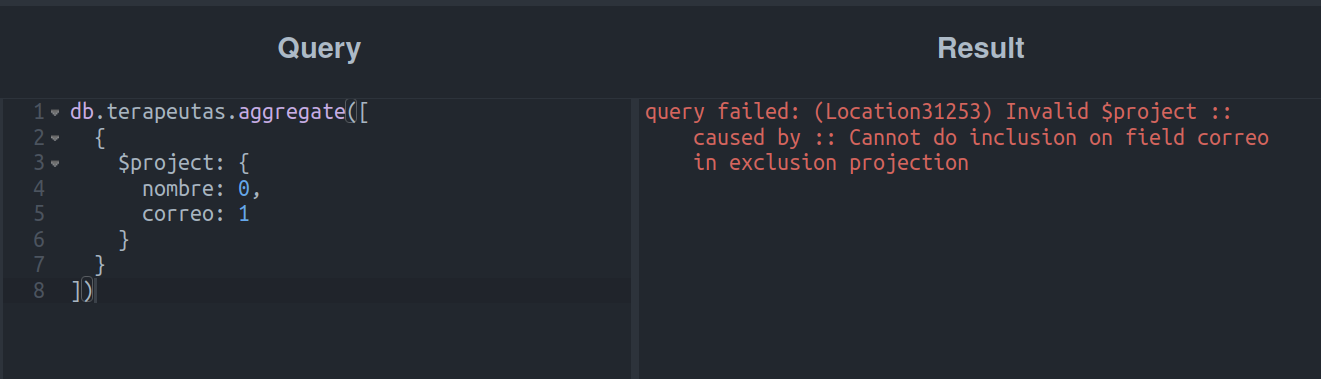
Okay, un error…
¿Y si intentamos invertir los valores de nombre y correo?
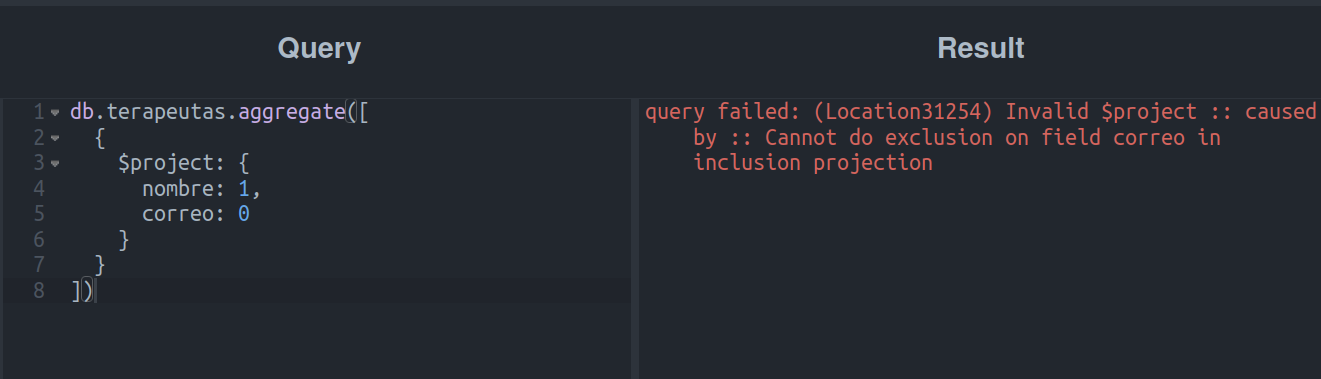
El resultado no parece haber mejorado en lo absoluto.
Veamos, en pocas palabras, el tío Mongo nos está diciendo que no podemos hacer inclusiones y exclusiones al mismo tiempo.
Tomando los anteriores ejemplos, podemos decir que la única manera de mezclar una exclusión y una inclusión es cuando la exclusión es para el campo _id.
Intentemos algo más interesante: obtengamos el listado de sesiones donde asisten los terapeutas Amelia Doe y John Freud Doe juntos en la misma sesión, en el resultado mostraremos los campos _id y horario únicamente. También agregaremos un campo nuevo que se llamará tipo, el cual contendrá el valor individual si solo un paciente asistirá a la sesión. En cambio, se usará el valor grupal si son dos pacientes o más.
Desglosemos un poco el problema, aquí necesitaremos:
- Filtrar con base en id de los terapeutas.
- Mostrar los campos horario y _id.
- Agregar un campo llamado tipo que tendrá valores variables, dependiendo de la cantidad de pacientes.
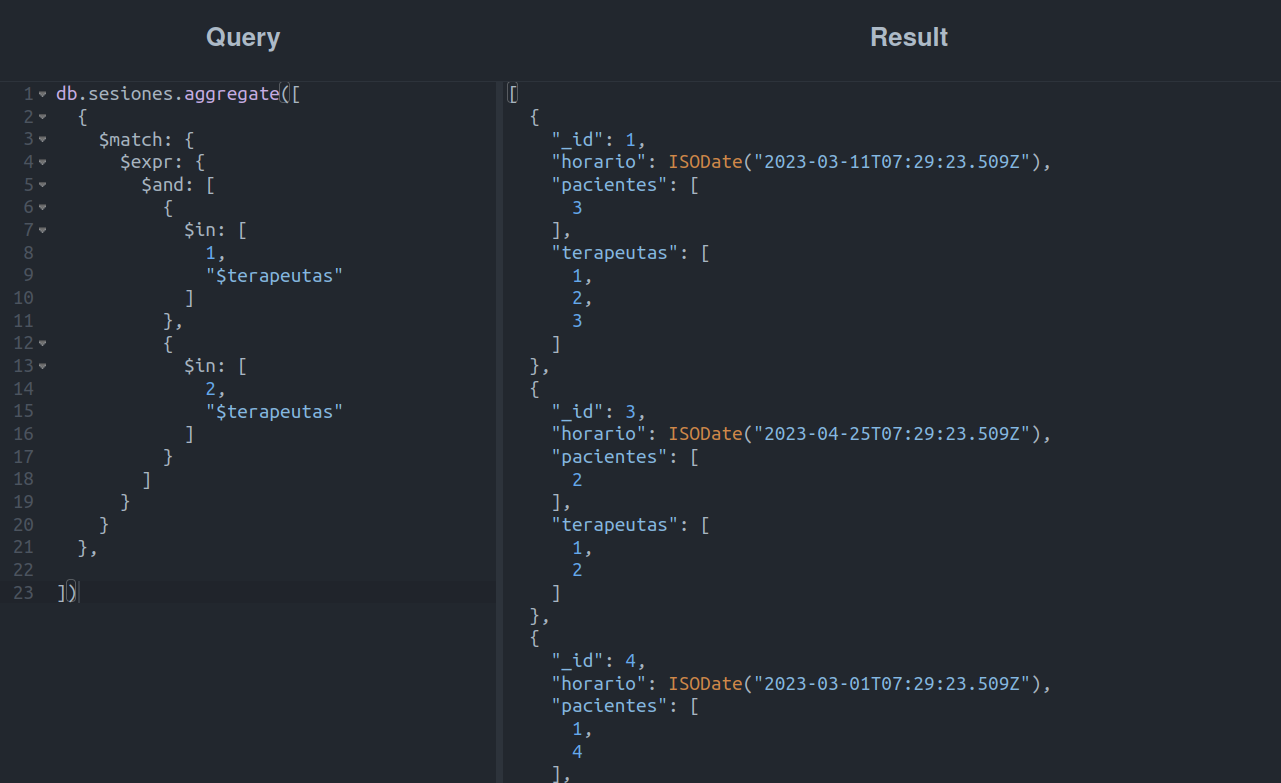
Hagámoslo por pasos: empecemos con el filtro de los terapeutas con una etapa $match y un par de conceptos nuevos:
Aquí tenemos un par de detalles nuevos:
- $and, esta expresión permite evaluar múltiples expresiones. Para que ésta sea verdadera, todas las expresiones en su interior deben ser verdaderas.
- $in, lo habíamos visto en su versión de operador. En este ejemplo es usado como una expresión, la cual será verdadera si el valor A se encuentra dentro del arreglo B.
Haciendo uso de estas dos herramientas podremos llegar al siguiente resultado:
Una vez concluida la etapa del filtro, es necesario agregar una segunda etapa para mostrar únicamente el campo horario:

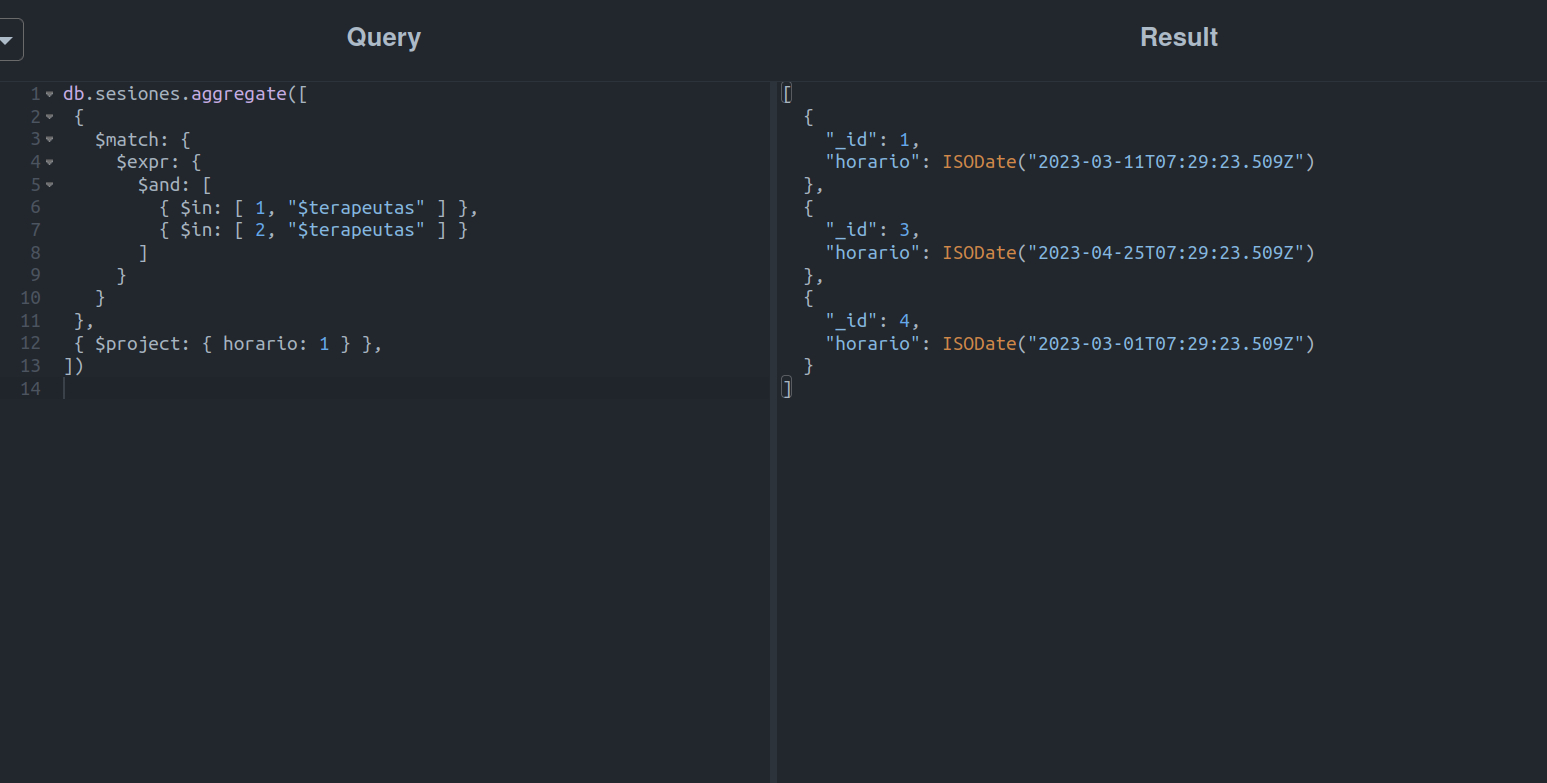
Hasta este punto, logramos satisfacer el primer y segundo puntos de los requisitos de la consulta. Solo falta agregar el campo extra que tendrá un valor basado en el número de pacientes de la sesión, algo que se realiza de la siguiente manera:

Para resolver este caso, se utilizaron operadores vistos anteriormente y algo nuevo:
- $cond, literalmente, es un operador ternario que nos permite obtener un valor A o B, dependiendo de si la condicional C es correcta o no.

Haciendo uso de la expresión $cond en combinación con $gt y $size, obtendremos la cantidad de pacientes y verificaremos que sean mayores a 1.
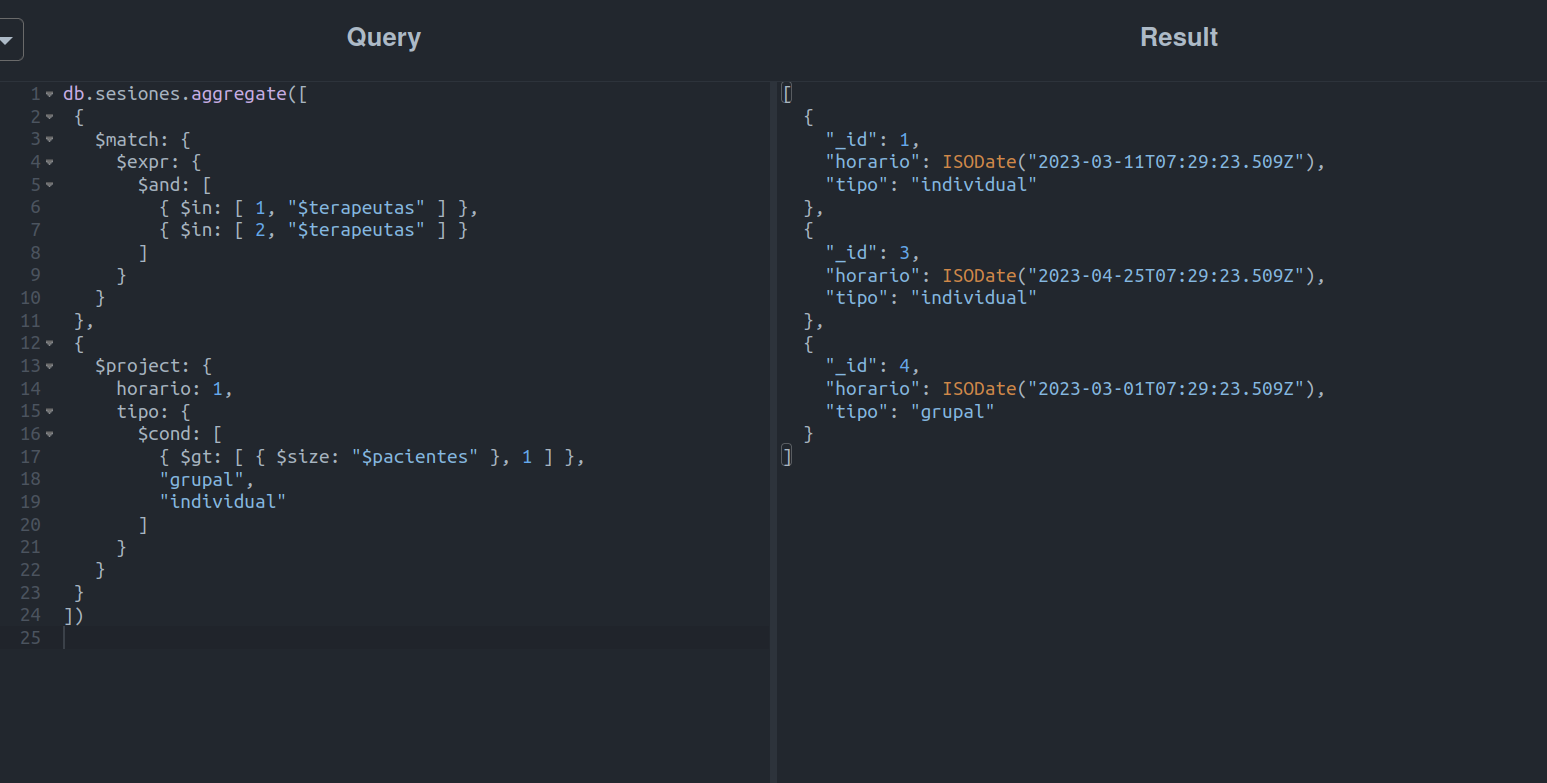
Y… ¡listo!
Tenemos una consulta que cumple con todos los requisitos propuestos y, algo mejor, nociones básicas del funcionamiento de los aggregates (operaciones de agregación) y algunos operadores super útiles para filtrar y procesar los documentos resultantes.
Así como los 2 tipos de etapas y diferentes operadores utilizados en este artículo, hay muchísimos más que podemos encontrar directamente en la documentación de MongoDB.

Como aportación final, si este artículo logró despertar tu interés y deseas saber cuál sería un buen paso para continuar, recomiendo aprender más sobre la etapa $lookup, debido a que sirve para buscar información en otras colecciones utilizando datos de los documentos de entrada. Además de manejar una pipeline interna para procesar los datos resultantes, simplemente es una herramienta necesaria y bastante potente.
¡Todo el éxito en tus proyectos! ¡Saludos!
Listopro Community da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.