Guía intermedia de Node.Js


Antes de comenzar, me gustaría destacar que este es el segundo artículo de una serie completa compuesta por tres partes. ¡Si te perdiste la primera parte, no te preocupes! Puedes acceder a ella en nuestro blog y asegurarte de tener una base sólida antes de sumergirte en las técnicas intermedias de Node.js.

Entonces, ¿por qué deberías interesarte en este lenguaje a nivel intermedio?
Bueno, Node.js se utiliza ampliamente para el desarrollo de aplicaciones de servidor, permitiéndote crear soluciones escalables y de alto rendimiento. Con su arquitectura basada en eventos y su capacidad de ejecutar código JavaScript tanto del lado del cliente como del servidor, Node.js se ha convertido en una elección popular para muchos desarrolladores.
Leyendo ese artículo que mencioné anteriormente, tendrás acceso a temas como: configuración del ambiente en varios sistemas operativos, puntos positivos de usar Node.js y la sintaxis básica del lenguaje.
En esta guía intermedia, abordaremos temas como la manipulación avanzada de archivos con el módulo "fs", la utilización de bases de datos y el streaming de datos de manera eficiente.
Con los siguientes temas, aprenderás a sacar el máximo provecho de Node.js y mejorar tus habilidades de programación.
Módulos y Habilidades intermedias de Node.js
Manipulación avanzada de archivos y directorios con el módulo "fs".
La manipulación avanzada de archivos y directorios es una tarea esencial en el desarrollo de aplicaciones con Node.js. El módulo "fs" (sistema de archivos) es una de las principales herramientas disponibles para manejar operaciones relacionadas con archivos y directorios. En esta guía intermedia, exploraremos las funcionalidades avanzadas del módulo "fs" y aprenderemos cómo utilizarlo de manera eficiente en nuestros proyectos.
El primer paso es asegurar que el módulo "fs" esté instalado en tu entorno Node.js. Afortunadamente, "fs" forma parte de los módulos principales de Node.js, por lo que no necesitas preocuparte por instalarlo por separado.
Puedes simplemente importarlo en tu código de la siguiente manera:

Ahora que tenemos el módulo "fs" disponible, podemos comenzar a explorar sus funcionalidades.
Para leer un archivo, podemos usar el método fs.readFile(). Este recibe la ruta del archivo que queremos leer y un “callback” que será invocado cuando la operación se complete. El “callback” recibe dos parámetros: un error, en caso de que ocurra, y los datos leídos del archivo.

De la misma manera, para escribir en un archivo, podemos utilizar el método fs.writeFile(). Este recibe la ruta del archivo en el que queremos escribir y los datos que deseamos grabar. Al igual que con fs.readFile(), también podemos pasar un callback para manejar posibles errores.

Además las operaciones básicas de lectura y escritura, el módulo "fs" también ofrece recursos avanzados, como re nombrar o mover archivos, crear y eliminar directorios, entre otros.
¡Vamos a explorar algunas de estas funcionalidades ahora!
Para re nombrar un archivo, podemos utilizar el método fs.rename(). Este recibe la ruta del archivo actual y el nuevo nombre que queremos asignarle. Esta operación es sincrónica y no requiere un callback.

Para crear un directorio, utilizamos el método fs.mkdir(). Este recibe la ruta del nuevo directorio que queremos crear y también puede recibir un callback para manejar errores.

¿Y si necesitamos eliminar un archivo o directorio? Para eliminar un archivo, utilizamos el método fs.unlink(). Para eliminar un directorio vacío, utilizamos el fs.rmdir(). Ambas operaciones también pueden recibir un callback para manejar errores.

Ahora que tienes un conocimiento intermedio sobre la manipulación avanzada de archivos y directorios con el módulo "fs", estás listo para aplicar estos conceptos en tus propios proyectos. Además, este conocimiento también te ayudará a agilizar tu trabajo con Node.js.
Trabajando con bases de datos utilizando Node.js, incluyendo bases de datos relacionales y NoSQL.
Trabajar con bases de datos es una parte fundamental del desarrollo de aplicaciones robustas y escalables. Node.js ofrece soporte para una variedad de bases de datos, tanto relacionales como NoSQL. En esta guía, exploraremos cómo utilizar Node.js para interactuar con estos dos tipos de bases de datos, proporcionando las herramientas necesarias para almacenar y recuperar datos de forma eficiente.
Comenzando con bases de datos relacionales, Node.js ofrece varias bibliotecas populares para conectarse e interactuar con bases de datos como MySQL, PostgreSQL y SQLite. Una de las bibliotecas más comunes es "node-mysql", que permite establecer conexiones con bases de datos MySQL y ejecutar consultas SQL de manera simple y eficaz.
Así, vamos a explorar las bases de datos SQL.
Para comenzar, necesitarás instalar la biblioteca "node-mysql" a través de npm (el gestor de paquetes de Node.js). Una vez instalada, puedes importar la biblioteca y configurar una conexión con tu base de datos de la siguiente manera:

Con la conexión establecida, puedes ejecutar consultas SQL para insertar, actualizar, recuperar y eliminar datos de la base de datos. Aquí hay un ejemplo simple de cómo ejecutar una consulta SELECT para recuperar datos de una tabla:

Ahora, vamos a explorar las bases de datos NoSQL.
En el contexto de Node.js, MongoDB es una opción popular para bases de datos NoSQL debido a su flexibilidad y facilidad de uso. Para interactuar con MongoDB, puedes utilizar la biblioteca "mongoose", que proporciona una capa de abstracción para simplificar la comunicación entre Node.js y MongoDB.
Al igual que con "node-mysql", necesitarás instalar "mongoose" a través de npm e importarlo en tu código. Luego, puedes establecer una conexión con MongoDB y definir un esquema para tus datos.
Ve un ejemplo básico a continuación:

Ahora puedes usar el "Model" para ejecutar operaciones de CRUD (creación, lectura, actualización y eliminación) en MongoDB. Aquí hay un ejemplo simple de cómo crear un nuevo documento:
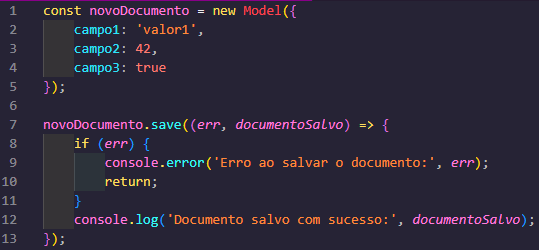
Con esta información, estás preparado para trabajar con bases de datos utilizando Node.js. Recuerda adaptar las configuraciones y ejemplos a la base de datos específica que estés utilizando.
Utilización de streaming de datos para procesar grandes volúmenes de información de forma eficiente.
La utilización de streaming de datos es una técnica poderosa para procesar grandes volúmenes de información de forma eficiente en Node.js. Al trabajar con datos en tiempo real, como la lectura de archivos grandes o la transmisión de datos por la red, el streaming permite procesar los datos a medida que son recibidos o leídos, en lugar de esperar a que el proceso se complete para comenzar a manipularlos.
Node.js proporciona la clase "Stream" como parte de su módulo "stream", que permite trabajar con streaming de datos. Existen dos tipos principales de streams: Readable e Writable. Un stream Readable se usa para leer datos de una fuente, como un archivo o una solicitud HTTP, mientras que un stream Writable se usa para escribir datos en un destino, como un archivo o una respuesta HTTP.
Supongamos que quieres leer un archivo grande y procesar los datos línea por línea. Podemos crear un stream Readable para leer el archivo y recibir eventos de datos a medida que se va leyendo.
Ve un ejemplo a continuación:

En este ejemplo, utilizamos el método createReadStream() del módulo "fs" para crear un stream Readable para leer el archivo. Luego, registramos un callback para el evento 'data', que se dispara cada vez que se lee un fragmento de datos. Dentro de este callback, procesamos cada línea del archivo. Finalmente, registramos un callback para el evento 'end', que se dispara cuando todo el archivo ha sido leído.
Ahora, abordemos el streaming de datos de escritura. Supongamos que quieres crear un archivo grande basado en datos generados dinámicamente. Podemos crear un stream Writable para escribir los datos en el archivo a medida que se van generando.
Ve un ejemplo a continuación:

En este ejemplo, utilizamos el método createWriteStream() del módulo "fs" para crear un stream Writable para escribir en el archivo. Luego, usamos un bucle para generar los datos y escribirlos en el stream mediante el método write(). Finalmente, llamamos al método end() para señalar el fin de la escritura.
Utilizar el streaming de datos en Node.js es un enfoque eficiente para procesar grandes volúmenes de información. Al utilizar streams, puedes ahorrar memoria, ya que no necesitas cargar todos los datos en la memoria de una sola vez. En su lugar, puedes procesar los datos a medida que llegan, haciendo que tu aplicación sea más eficiente y escalable.
Recuerda explorar las diferentes funcionalidades del streaming de datos en Node.js, como el encadenamiento de múltiples streams, el uso de streams "transform" para procesar datos en tiempo real y el manejo adecuado de eventos y errores.

Con esta información, estás listo para utilizar el streaming de datos para procesar grandes volúmenes de información de forma eficiente en tus proyectos Node.js. Aprovecha los beneficios del streaming y crea aplicaciones que manejen datos de manera rápida, eficiente y escalable.
Ahora que ya has explorado algunos temas esenciales a un nivel intermedio, estás listo para avanzar al siguiente nivel de nuestra guía de Node.js. En el próximo artículo, profundizaremos en conceptos más avanzados y abordaremos técnicas que elevarán tus habilidades a un nuevo nivel.
¡Así que aquí concluimos la guía de hoy!
A medida que avanzamos a la siguiente parte de esta serie, asegúrate de estar preparado para explorar temas avanzados y descubrir los secretos del desarrollo de alto nivel en Node.js. ¿Qué opinan de las guías recientes de Node.js? Cuéntamelo en los comentarios del post.
Listopro Community da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.