En las fauces de Asp.Net: desde el fondo hacia la superficie


Este artículo busca mostrar cómo funcionan las aplicaciones escritas con Asp.Net desde un punto de vista más profundo y fundamental, como el funcionamiento de los protocolos TCP y HTTP hasta lo más superficial, es decir, el funcionamiento de requests, el view engine y cómo lo interpreta el navegador.
Esto podría parecer básico o esencial, pero el desarrollador promedio de Asp.Net suele desconocer a profundidad estos conceptos, debido a que tanto los IDEs como el framework .Net suelen abstraer esto para facilitar el desarrollo de web apps y aumentar la velocidad de trabajo, por lo que si bien puedes hacer web apps poderosas con .Net, no necesariamente habrás estudiado o investigado estos conceptos básicos. Con esto no quiero decir que no conocer completamente el funcionamiento de las web apps de .Net esté mal, pero saberlo hará la diferencia de calidad en las apps que hagas, al tiempo que entenderás más rápido los errores que te tomarían investigar más de una tarde.
Si llevas tiempo creando aplicaciones en .Net notarás que, al iniciar un nuevo proyecto, te solicita que especifiques cuál tipo de proyecto deseas crear: ASP.NET Core Empty, MVC, Web API, Forms, Tests, etc. (Puedes verlo con el comando dotnet new --list). Aunque resulte obvio—puede que mucha gente no lo sepa—, todos y cada uno de ellos son lo mismo: se llaman templates o plantillas y son programas precodificados, listos para incorporar la lógica que necesitemos para crear un producto de software. Vamos a concentrarnos en los templates de ASP.NET Core y semejantes para entender a profundidad cómo es el flujo de las peticiones desde tu servidor hasta tus clientes, tomando un acercamiento desde lo más fundamental a lo que más utilizas en tu día a día como desarrollador de .Net.
Problema de completitud
Usualmente, incluso cuando llevamos años desarrollando aplicaciones ASP.NET, nuestro entendimiento de cómo funcionan las web apps está bien, pero es un conocimiento incompleto. Por ende, bajemos por capas el nivel de complejidad de donde estás hasta tener una visión holística. Una aplicación web es, básicamente, una aplicación de tipo TCP (Protocolo de Control de Transmisión) con uno o varios eventos esperando mensajes.
¿Qué implica eso? Que se mantienen esperando en una IP y en un puerto todo lo que reciban, porque de eso dependen sus acciones posteriores. Grosso modo, una aplicación TCP puede esperar todo tipo de dato y responder todo tipo de dato, lo que implica que lo que reciben son bytes y lo que devuelven son bytes. Lo anterior se moviliza a través de un network stream, similar a los file stream y a los memory stream. Los streams son APIs que permiten, mediante código, enviar bytes a través de un bus (componente del PC que comunica eléctricamente distintos dispositivos de hardware) de un lado a otro.
En el caso de los network streams, pasan de la memoria a la red, mientras que los memory van de espacio de memoria a espacio de memoria y los file stream de la memoria al disco. Básicamente, una app web es un programa como cualquier otro, razón por la que segmentaciones como API web, Web Apps Backend o Frontend (entre otras) pierden sentido en este nivel de complejidad.
De TCP a HTTP
Aumentemos la complejidad. Lo único que entiende una aplicación TCP es una dirección IP y un puerto. Sin embargo, sobre este protocolo se insertó otro, el HTTP. Entonces una app HTTP es un programa como cualquier otro con eventos basados en un string (la URL), aunque realmente acepta todo como en la TCP. Lo único distinto es que en su interior tiene un switch case con strings específicos (las URIs) y dentro de cada caso otro switch case adicional con los verbos (GET, POST, PUT, PATCH, DELETE, entre otros).
Elevemos aún más la dificultad al hablar sobre cómo operan los framework web (en este caso, .NET). Microsoft nos abstrae de los 2 niveles de complejidad anteriores haciendo librerías y plantillas de código para crear programas que se comporten como programas TCP, pero usando el protocolo HTTP. Para lograrlo, hay muchísimas formas y hace tiempo hubo un debate sobre cómo desarrollar estas apps, sea por configuración (declarar de forma explícita las URL y demás funcionamiento) o por convención (el framework tiene comportamiento general implícito y solo declaras lo que necesitas).
Si te das cuenta, las "minimal API" son un ejemplo de configuración, es decir, debes declarar, necesariamente, la ruta deseada para cada callback, mientras que el famoso "MVC" es un ejemplo de convención: usas una forma previamente diseñada por otras personas (el equipo de Microsoft) y basada en una metodología muy aceptada para seguir sus indicaciones (por ejemplo, el routing es controller/action).
A grandes rasgos, ambos son lo mismo programas HTTP que:
- Escuchan un evento para ejecutar código.
- Hacen switch case con el string que le sigue a su host (una dirección DNS o IP con puerto).
- Hacen otro switch con el verbo contenido en los bytes de la recepción.
- Ejecutan según lo que fueron programados.
Al final del día, una web solo abre un network stream y, si llegan bytes, ejecuta los eventos.
El flujo en el protocolo HTTP
Como he mencionado, todo lo que está aplicado sobre TCP funciona muy similar: espera bytes de un network stream, ejecuta lo necesario y listo, pero no es suficiente. Ahí es donde viene a colación la arquitectura cliente-servidor. En esa arquitectura, lo esperado es que un servidor además de ejecutar acciones cuando reciba bytes (en paquetes), también los envíe de vuelta por el mismo stream. A eso lo conocemos como request/response: cuando llegan los bytes se llama request, a la ejecución del evento se llama proceso o ejecución y cuando el programa lanza los bytes de regreso se llama response.
HTTP no es el único protocolo que funciona así. De hecho, otros como el POP (empleado para correos) funcionan de la misma manera. El asunto está en que el motivo por el cual surgió esta arquitectura era la necesidad de centralizar la información y ello sólo fue posible cuando las computadoras personales se hicieron más poderosas y pequeñas. Estos programas, llamados clientes (como el navegador o programas que usen librerías para comunicarse), abren un network stream en la dirección del programa (al que ahora llamaremos servidor). El servidor acepta esos bytes, ejecuta lo concerniente y envía bytes de vuelta. Así de simple.
Esos bytes se utilizan para ejecutar el proceso y, cuando se creó el protocolo HTTP, se decidió la forma en la cual se ordenarán esos bytes: la URI, el verbo, los headers y el body (hay más elementos, pero los anteriores son los más utilizados). El programa server, ya diseñado para trabajar con HTTP este:
- Recibe esos bytes.
- Toma el área asociada a la URI y hace un switch case.
- Si la URI está dentro de los casos, revisa el verbo y hace otro switch case.
- Si el verbo está dentro de los casos ejecuta para lo que está programado usando los headers y el body.
- Luego enviar al stream en dirección opuesta los bytes que llamaremos respuesta.
Las .NET Templates desde adentro
Elevemos todavía más la complejidad a los mismos estándares del equipo de .NET. Si te fijas bien, notarás que los términos Razor page, web API, MVC, API+React, y API+Angular (puedes corroborarlo con el comando dotnet new --list) son prácticamente lo mismo, pero en formato distinto. Veamos, por ejemplo, a una minimal API, donde un request es simplemente una función (digo función en vez de método porque tiene un acercamiento más de paradigma funcional que de poo) donde su nombre es Map + Verbo, cuyos parámetros son la URI y un callback que define el comportamiento y respuesta de esa URI. Por otro lado, las MVC son clases que servirán como colecciones de métodos para definir comportamientos y respuestas, cuya URIs definida por convención basándose en el nombre de la clase y del método y el verbo es definido por un atributo (aquel elemento descrito con corchetes encima del método por ejemplo [HttpGet]).
Las Razor pages usan naming convention para la URI, así como los métodos OnVerbo como definición de comportamiento y respuesta. Finalmente, las API web (que ni siquiera es una forma de cómo organizar, se usan las anteriores mencionadas, lo de web api es como se configuran los bytes que llegan y se disparan o más bien el cómo se configuran los request y response.
El navegador es el cliente más versátil
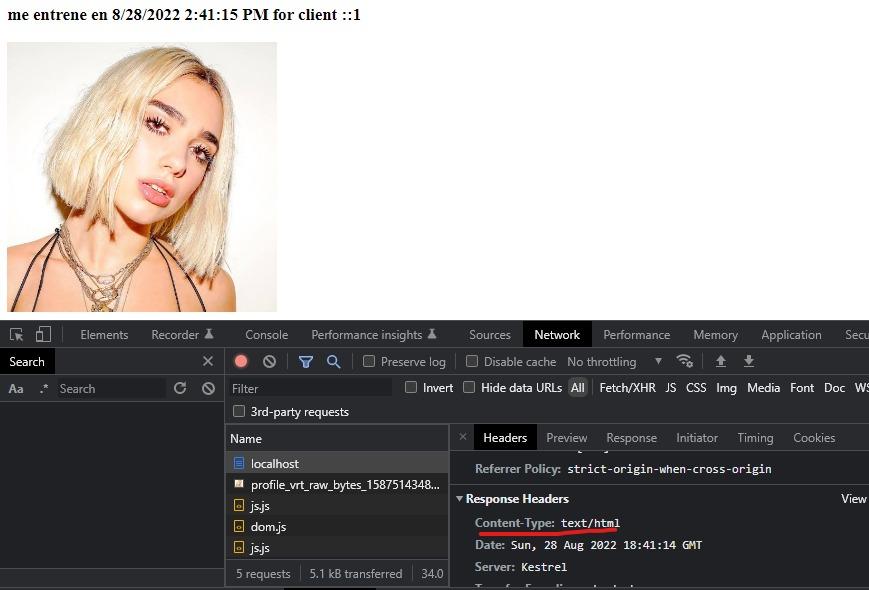
Es momento de abordar HTML. Hasta ahora sabemos que nuestro programa espera y envía bytes, así como nosotros podemos decidir en la programación la forma en la que se envíen dichos bytes, quienes deciden qué hacer con lo que enviamos son los clientes. Observa esta imagen:

Ahora esta imagen:

Ambas poseen el mismo body pero se muestran de forma distinta porque tienen headers distintos. El navegador está diseñado para ser el cliente HTTP perfecto y programado de forma distinta basándose en los bytes de respuesta, específicamente lo que viene en el header:
- Si viene text/plain, solo pone el texto sin ningún formato(por eso puedes ver que aparecen las etiquetas </> html)
- Si viene imagen, solo agrega la imagen.
- Si viene application/octet-stream, realiza una descarga de archivo.
- Si viene text/html, configura un DOM y muestra cómo se ve.
- Si viene application/json, haz exactamente lo mismo que con text/plain.
Ahora ¿por qué no usamos text/plain en lugar de application/json si ocurre exactamente lo mismo? Pues porque muchos clientes están configurados para automáticamente deserializar json si leen un header application/json, incluso en JavaScript.

Y hablando de DOM, sucede que es el responsable de que cuando se escriba un string en formato HTML en el navegador lo pase al motor de Javascript y éste comience a crear objetos (JS objects) para que se vean gráficamente, instancias muy parecidas al código en Windows Forms con sus propiedades, métodos y eventos para cada uso.
Estos objetos están dispuestos en una estructura de datos en la que una de sus propiedades tiene una colección o arreglo (children) con los elementos por debajo de su jerarquía, al tiempo que éstos a su vez también poseen esta propiedad con otros elementos y la propiedad (parent) con la referencia en memoria de aquel objeto que lo contiene en su propiedad children. El query selector y el método getElementById son APIs que utilizan un patrón para evitar navegar manualmente entre las propiedades ya mencionadas.
La responsabilidad de ASP.NET termina con la respuesta
Inmediatamente, nuestro server dispara en esos bytes la responsabilidad de todo lo que ocurra no es de nuestro server. Solo es una máquina que recibe y envía elementos, nada más. Y te preguntarás: en Razor, ¿por qué soy capaz de escribir código c# y éste se ve reflejado en el navegador? Muy sencillo: la ejecución de ese código c# se realiza durante el proceso, es decir, después de recibir el request, pero antes de disparar el response, mediante algo que se llama view engine. El de .NET se llama Razor.
Cada vez usas Asp-for o @Html.EditorFor(m=> m.Name), su ejecución ocurre en MVC con el método View() y en Razor pages al final del método OnGet. Ahora bien, ¿qué sucede al final de estos métodos? En realidad, El método View() es una respuesta con status code 200 (parte de nuestros bytes de respuesta),content-type (header de respuesta) text/html, la cual, antes de disparar la respuesta el:
- Lee el archivo de view (.cshtml).
- Ejecuta el código c# que está dentro (lo que quiere decir que si hay un bucle que llena la tabla lo sustituye por el string correspondiente a los elementos de esa tabla, según la data en el objeto model que utilices).
- Busca su layout y, si no tiene le pone el que está por defecto.
- Coloca ese string completo en formato html dentro del body y junto con todos sus headers, status code cookies y demás elementos que tiene que llevar el paquete http de respuesta conforme a como hemos programado nuestro server lo dispara al cliente que hizo el request.
Finalmente, si nuestro cliente es un programa que usa una librería de HTTP, solo recibe la respuesta en texto y luego hace con ese texto lo que sea para lo que fuese creado, al tiempo que si la recibe un navegador su motor de js (o el que tenga), se encarga de crear los elementos en memoria y éstos a su vez se dibujan en la pantalla, como mencionamos en la sección anterior.
Ahora, con el entendimiento de todo lo que sucede entre tus clientes y tu server, será mucho más fácil hacer debug de todas tus aplicaciones escritas en ASP.NET.
Nos vemos en una próxima entrega.
Revelo Content Network da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.