Disponibilizando un modelo de clasificación (Keras + Flask + Heroku)


Desde que comencé a estudiar Machine Learning pensé en cómo iba a poner a disposición el modelo de clasificación que entrené para que fuera accesible para usuarios o aplicaciones. La principal barrera con la que me encontré fue el hecho de que la aplicación web que usaría el modelo de clasificación no estaba hecha en Python, por lo que no fue posible simplemente llamar al clasificador en un controlador o servicio.
En estos casos, la solución fue crear una API que sirviera únicamente con el propósito de recibir una solicitud con los atributos de un nuevo ejemplo y devolver el resultado generado por el clasificador. Como el propósito de la API es muy simple, busqué un framework que cumpliera solo con este objetivo y así me encontré con Flask.

Flask
Flask es un micro-framework escrito en Python que simplifica el desarrollo de APIs, permitiendo iniciar un proyecto de manera sencilla e irlo evolucionando a medida que surgen nuevas necesidades, como la adición de un ORM, si es necesario persistir información en una base de datos.
Creación y persistencia de un modelo pre entrenado
Comenzaremos con la implementación del modelo de clasificación y, dado que el enfoque del artículo es la puesta a disposición del modelo, no daré tanta énfasis a la parte de Machine Learning. Primero debemos crear un nuevo directorio para nuestro proyecto; recomiendo el uso de virtualenv para aislar la instalación de las bibliotecas y de Python que vamos a utilizar.

Con el proyecto creado, debemos inicializar el repositorio git para que los archivos se versionen mediante la ejecución del comando git init dentro del directorio del proyecto. Con el repositorio git creado, modificaremos el archivo .gitignore para que los archivos generados por virtualenv sean ignorados.

Como utilizaremos la base de datos IRIS, que es ampliamente usada para la evaluación de modelos de clasificación, la forma más sencilla de cargarla es a través de la biblioteca scikit-learn. La otra biblioteca que usaremos será tensorflow-cpu, que es una biblioteca utilizada en proyectos de Deep Learning, pero utilizaremos una API de alto nivel llamada keras, que simplifica el desarrollo de redes neuronales.
Antes de continuar, vale la pena aclarar el motivo por el que estamos trabajando con tensorflow-cpu y no con tensorflow. En primer lugar, por la falta de una GPU y las instalaciones necesarias para que tensorflow se ejecute a través de la GPU, y en segundo lugar, el tamaño máximo permitido por Heroku para una aplicación después de instalar sus dependencias y compresión, que al momento de escribir este artículo es de 500 MB y solo la biblioteca tensorflow ocupa aproximadamente 600 MB. Sin embargo, es posible usar tensorflow durante el desarrollo del modelo utilizando GPU durante las etapas de entrenamiento y prueba, y una vez finalizado, usar tensorflow-cpu en producción.
Después de ejecutar el comando pip install scikit-learn tensorflow-cpu para instalar las bibliotecas necesarias, crearemos un nuevo archivo llamado classifier.py donde entrenaremos y guardaremos nuestro modelo de clasificación.
El código a continuación define una red neuronal que contiene dos capas ocultas con 128 y 64 neuronas, respectivamente. Ambas capas aplican la función de activación ReLu y tienen los valores de los pesos inicializados usando la técnica RandomNormal, que está fijada con una SEMILLA para que el resultado sea reproducible. Dado que la base IRIS contiene tres clases, la última capa tiene tres neuronas y utiliza la función de activación softmax.
Después de compilar y entrenar la red neuronal, se alcanzó una precisión de 0.966 en el grupo reservado para prueba, lo cual es suficiente para el objetivo de este artículo. Con esto, al final del script guardamos un archivo llamado model.h5 que contiene nuestro modelo entrenado. Existen otras métricas y arquitecturas que pueden ser probadas y generar mejores resultados, pero nuestro enfoque es la disponibilidad de un modelo ya entrenado y no encontrar el mejor modelo de clasificación.


API Flask
Con nuestro modelo entrenado, llegó el momento de crear una API para ponerlo a disposición. Como se mencionó anteriormente, utilizaremos el micro-framework Flask para crear la API, así que el primer paso es instalar Flask ejecutando el comando pip install flask.
Una vez instalado, se creará un archivo llamado main.py, que contendrá el siguiente código. En este código se declara la ruta /predict que responde al método HTTP POST, y al recibir una lista de atributos de un ejemplo de la base de datos IRIS, devuelve una lista con la probabilidad de cada una de las clases posibles.


Como se describe en los comentarios del código, aquí algunos puntos importantes:
- El modelo se carga antes de inicializar la aplicación, ya que este proceso es costoso y hacerlo en cada solicitud aumentaría considerablemente el tiempo de respuesta de la API;
- El resultado del método keras.Sequential.predict() debe convertirse a un objeto tipo lista, ya que la función jsonify no puede serializar objetos numpy.
La aplicación se inicia ejecutando el comando python main.py, y queda disponible en localhost:5000. Para probar la API, basta con hacer una solicitud ejecutando el siguiente comando cURL o utilizando aplicaciones como Postman o Insomnia.

Despliegue en Heroku
Con la API completada, es momento de hacer el despliegue en la plataforma Heroku. Heroku es una Plataforma como Servicio (PaaS) que proporciona un entorno en la nube utilizado para el aprovisionamiento de aplicaciones web. Debido a su simplicidad y baja necesidad de configuraciones, es una buena opción para quienes buscan poner una aplicación web a disposición sin dedicar mucho tiempo a la configuración del entorno.
Antes de crear la aplicación en Heroku, es necesario hacer algunos ajustes en la API para prepararla para el entorno de producción. El primer paso es instalar el servidor WSGI para atender la advertencia que aparece al iniciar la aplicación. Dicha advertencia dice: “WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead”, indicando que el servidor actual debe usarse solo en desarrollo y que para el entorno de producción se debe agregar un servidor WSGI propio, que en este caso será gunicorn.
Al finalizar la instalación de gunicorn, generaremos un archivo .txt con todas las dependencias de nuestra aplicación ejecutando el comando pip freeze > requirements.txt. Observa que se generó un archivo llamado requirements.txt que contiene la lista de dependencias, así como la versión específica de cada biblioteca.
Finalmente, es necesario definir que la aplicación se inicie usando el servidor gunicorn, esto se hace agregando una línea con la configuración web: gunicorn main:app a un archivo llamado Procfile. El arcuivo Procfile es utilizado por Heroku para definir las configuraciones de inicio del entorno.
Como haremos el despliegue a través de la integración de Heroku con Github, será necesario hacer un commit con los cambios hasta aquí y crear un nuevo repositorio como el que creé con el código de este proyecto.
Con tu cuenta en Heroku creada a través de este link, llegó el momento de hacer el despliegue de la aplicación. Al hacer clic en el botón new y seleccionar la opción Create new app, serás redirigido a la pantalla de creación de una nueva aplicación. Recuerda que ya no existen Dynos gratuitos, y un Dyno básico es suficiente para reproducir la aplicación descrita en este artículo, con un costo aproximado de siete dólares por mes.

Ahora se debe completar un nombre para la aplicación, que en mi caso fue `iris-prediction-api`. Como el nombre es único, debe elegirse algo que tenga sentido para tu aplicación.

Con el nombre de la aplicación definido, llegó el momento de enviar nuestro código a Heroku. Es posible hacerlo a través de un cliente de terminal que el mismo Heroku proporciona, pero lo haremos mediante la integración con Github. Para ello, haz clic en la opción `Github` que se encuentra en la sección `Deployment method` y sigue los pasos para dar acceso a Heroku a tus repositorios en Github.
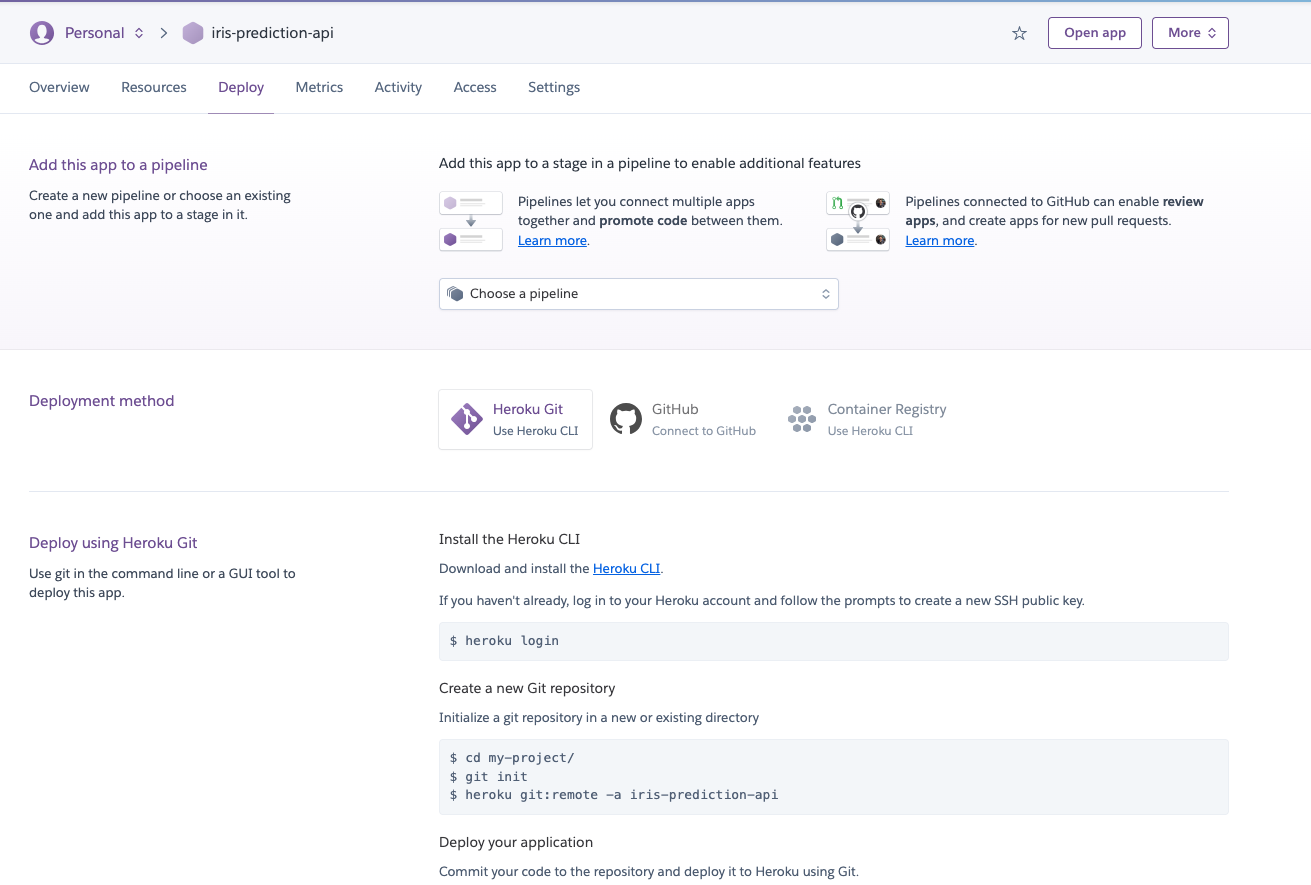
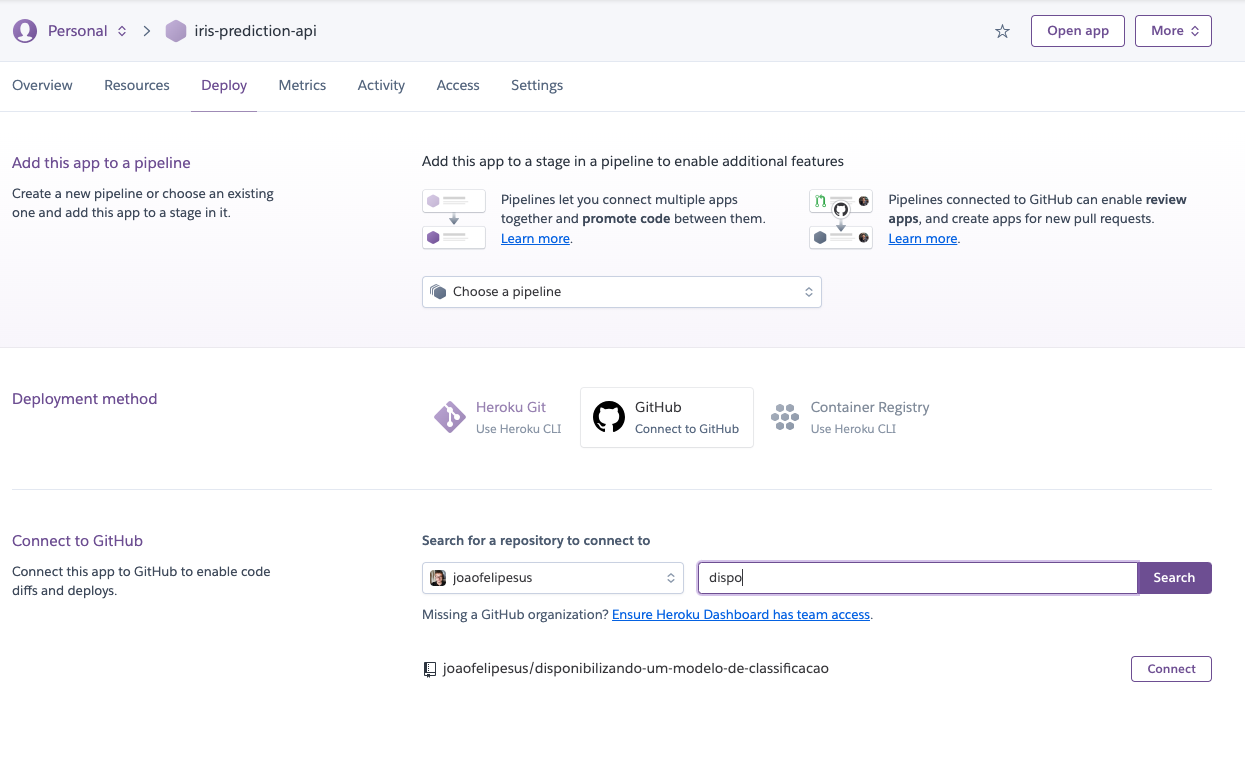
Una vez que la integración esté completa, utiliza el filtro para seleccionar el nombre del repositorio y haz clic en `connect`. Después de conectar el repositorio, selecciona la `branch` que contiene el código de producción, que en mi caso es la branch `main` y haz clic en el botón `Deploy branch` para iniciar el proceso de despliegue. Ten en cuenta que existe una opción que permite activar el despliegue automático, de modo que cada vez que se actualice la branch seleccionada, se realizará un nuevo despliegue automáticamente.
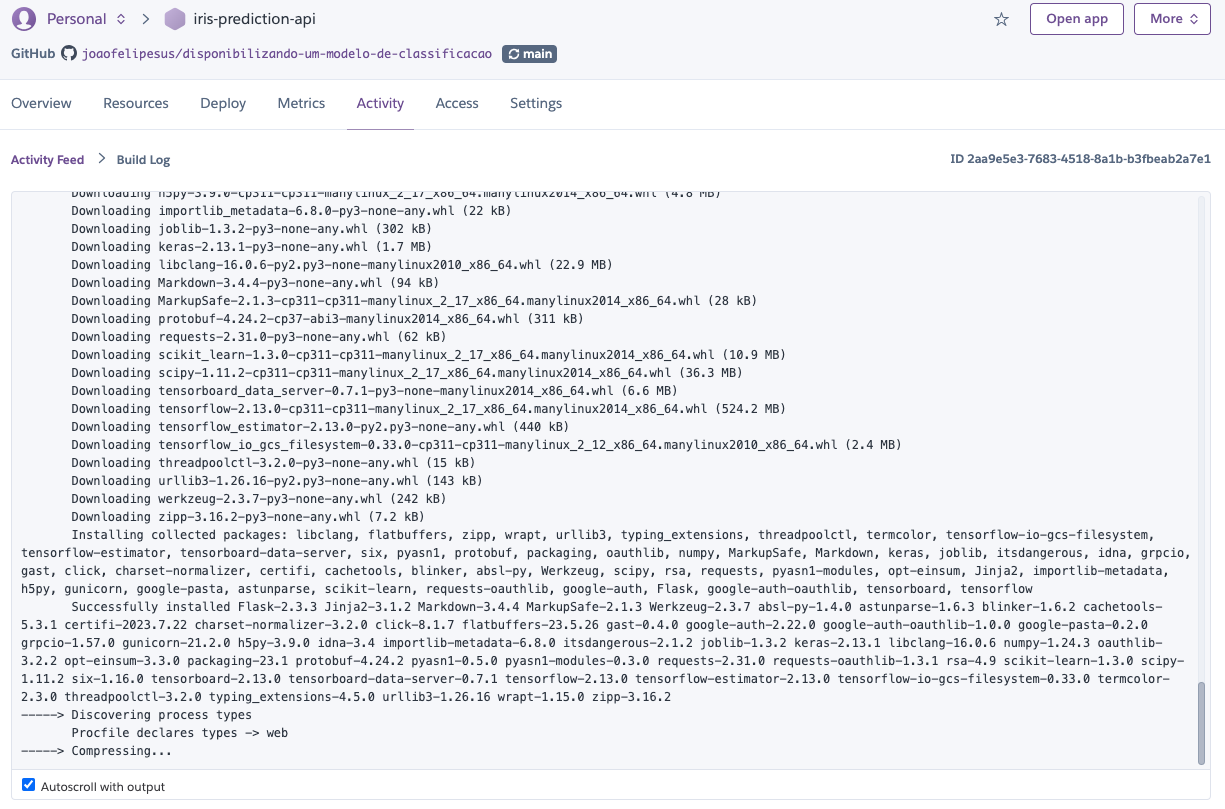
Es posible monitorear los pasos que se están ejecutando y el estado del `despliegue`.
Con la etapa de despliegue terminada, es momento de probar si la API está funcionando correctamente. Haz clic en el botón `Open app` y copia la `URL` de la pestaña que se abrió. Esta es la `URL` que apunta a la API y, con ello, es posible hacer una solicitud usando cURL apuntando al servidor de producción.


Por último, tenemos una API en Flask que pone a disposición un modelo de clasificación para que sea utilizado por otras aplicaciones. El código utilizado como ejemplo a lo largo del artículo está en este repositorio.
¡Hasta el próximo artículo!
Listopro Community da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.