Desplegando infraestructura como código en AWS


La infraestructura como código es cada día más demandada. Sin importar si eres Cloud Architect o Cloud Developer, las empresas requieren que tengas experiencia desplegando infraestructura como código por las diferentes ventajas que eso representa.
Algunas ventajas de lo anterior son:
- Reconstruir un servicio en la nube: Ya sea que tengas tu entorno de desarrollo y productivo en diferentes regiones o cuentas, podrás desplegar tu servicio con un par de comandos.
- Verificar la configuración: Podrás ver la configuración de tu servicio de forma fácil y, de ser necesario, cambiarla para volverlo a desplegar.
- Aprovisionar el despliegue en la nube: de forma sencilla y rápida, ya que es la herramienta quien se encarga de realizar todo.
- Cambiar de proveedor: Muchas veces suele resultar difícil migrar una arquitectura de un proveedor a otro. Herramientas como Terraform o Serverless Framework permiten una migración sencilla.
- Tiempo: El despliegue de nuestra infraestructura como código es más rápido que realizarla mediante consola.

Existen diferentes herramientas que permiten trabajar toda la arquitectura que necesitas de forma fácil y sencilla, sin necesidad de utilizar la consola o dashboard de tu proveedor. Nos centraremos en Serverless Framework para desplegar algunos servicios de Amazon Web Services (AWS) como Bucket de S3, SQS y DynamoDB. Serverless Framework no solo lo utilizaremos para desplegar nuestra infraestructura como código, si no también para nuestros permisos y funcionalidades, de modo de aprovechar la mayoría de recursos o servicios que ofrece AWS.
El proceso de instalación de Serverless Framework es sencillo: puedes utilizar la documentación oficial para hacerlo.
El archivo serverless.yml buscará Serverless Framework para saber qué desplegar y cuál es la configuración del mismo. Para crearlo, podemos utilizar una plantilla predeterminada, pero lo recomendado es hacer nuestro archivo desde cero. No es algo complejo, pero sí nos permitirá comprender totalmente lo que desplegamos. Este archivo tiene una estructura que debemos cumplir, la cual puede variar un poco dependiendo de lo que necesitemos desplegar, entiéndase infraestructura, permisos o funciones.
Cuando desplegamos recursos con alguna herramienta, CloudFormation crea buckets con el nombre del servicio para guardar la configuración, el estado, etc. Estos buckets son importantes para el despliegue de nuestros proyectos.
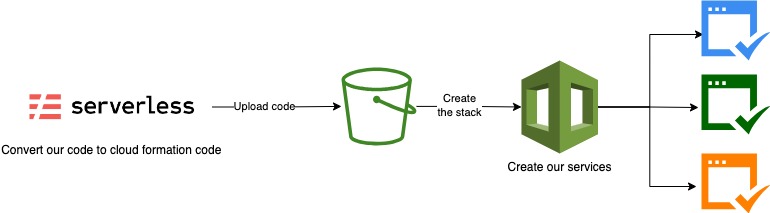
Estructura del archivo serverless.yml
Nombre del Proyecto: service
El proyecto service generará un bucket de S3, que será utilizado por CloudFormation para verificar el despliegue anterior y compararlo con el despliegue actual. Esto permite agregar, modificar o eliminar elementos en nuestra infraestructura de manera eficiente.
Configuración del Proveedor
En la sección provider, configuraremos los detalles de nuestro proveedor de servicios. Esto incluye el nombre, el lenguaje y version (runtime), la etapa (stage) de nuestro proyecto y la región en la que deseamos que se despliegue.
Personalización del Proyecto
En el bloque custom tenemos la opción de configurar variables para diferentes ambientes. En el código anterior, hemos establecido que la región donde deseamos que se despliegue nuestra infraestructura será dinámica y estará ubicada en: custom.config.dev/prod.my_region. Esto nos permite hacer despliegues a entornos de desarrollo (dev) o producción (prod) sin preocuparnos por cambiar manualmente los valores de las variables.
Inicio de la Infraestructura
En la sección resources es donde escribiremos nuestra infraestructura. Sin embargo, es una buena práctica separar nuestro código en archivos modulares.
Para hacer uso de estos archivos, debemos ubicarlos en el mismo directorio que nuestro archivo serverless.yml e importarlos con la sintaxis ${file(filename.yml)}. Dado que resources es una lista, debemos anteponer - al nombre de nuestro archivo para incluirlo correctamente.
# Nombre del proyecto
service: nombre-de-mi-proyecto-infra
# Configuración del proveedor
provider:
name: aws
runtime: python3.8
stage: ${self:custom.stage, 'dev'}
region: ${self:custom.config.${self:custom.stage}.my_region}
# Personalización del proyecto
custom:
stage: ${opt:stage, ‘dev’}
config:
dev:
account_id: ''
my_region: ${opt:region, 'us-east-2'}
prod:
account_id: ''
my_region: ${opt:region, 'us-east-1'}
Este pequeño ejemplo solo contiene dos variables que pueden cambiar dentro de custom: el id de la cuenta y la región, pero esto no significa que no podremos agregar más variables, las cuales son, en su mayoría, las que necesitamos configurar de forma separada.
# Inicio de infraestructura o recursos
resources:
- ${file(s3.yml)}
En la sección de resources ya no utilizaremos archivos YAML tradicionales, sino que haremos uso de la sintaxis de CloudFormation. Esta sintaxis está basada en CamelCase, con algunas pequeñas variaciones para agregar elementos como etiquetas.
En nuestro archivo s3.yml, tendremos la posibilidad de crear múltiples buckets, pero es importante recordar que no solo debemos cambiar el nombre del bucket, sino también el identificador del recurso, referido a cómo se nombra dentro de nuestro proyecto de Serverless. Es crucial que estos elementos tengan nombres únicos.
S3.yml
Resources:
S3Bucket:
Type: 'AWS::S3::Bucket'
DeletionPolicy: Delete
Properties:
BucketName: my-first-bucket
S3Bucket2:
Type: 'AWS::S3::Bucket'
DeletionPolicy: Delete
Properties:
BucketName: my-second-bucket
Con estas configuraciones, podrás desplegar dos buckets de S3 en AWS de manera independiente, sin importar la cuenta o la región en la que te encuentres.
Es importante considerar que los buckets en S3 son elementos globales, lo que significa que su Amazon Resource Name (ARN) no está asociado a una cuenta o región específica. Por lo tanto, puedes crearlos y acceder a ellos desde cualquier cuenta o región en la que tengas acceso.
Si deseas tener diferentes buckets para los entornos de desarrollo (dev) y producción (prod), puedes hacerlo dinamizando el nombre de los recursos y configurándose en la sección custom. De esta manera, podrás ajustar los nombres de los buckets según tus necesidades y requerimientos específicos para cada ambiente.
Con estas consideraciones, podrás tener la flexibilidad necesaria para gestionar tus buckets de S3 en AWS de forma adecuada y adaptarlos según las necesidades de tu proyecto y entornos. Recuerda siempre seguir las buenas prácticas de seguridad y asegurarte de que los permisos y políticas de acceso estén correctamente configurados para cada bucket en la nube.
Custom refactorizado:
custom:
stage: ${opt:stage, ‘dev’}
config:
dev:
account_id: ''
my_region: ${opt:region, ‘us-east-2'}
my_first_bucket: my-first-dev-bucket
my_second_bucket: my-second-dev-bucket
prod:
account_id: ''
my_region: ${opt:region, 'us-east-1'}
my_first_bucket: prod-bucket-name-1
my_second_bucket: prod-bucket-name-2
Para aplicar estos cambios debemos aplicar las variables dinámicas a nuestro archivo:
S3.yml:
Resources:
S3Bucket:
Type: 'AWS::S3::Bucket'
DeletionPolicy: Delete
Properties:
BucketName: ${self:custom.config.${self:custom.stage}.my_first_bucket}
S3Bucket2:
Type: 'AWS::S3::Bucket'
DeletionPolicy: Delete
Properties:
BucketName: ${self:custom.config.${self:custom.stage}.my_second_bucket}
Con esto estaríamos listos para desplegar buckets a dos diferentes ambientes dev/prod sin la necesidad de cambiar código de nuestros archivos Yaml.
Comando para desplegar nuestros buckets
Ambiente dev:
serverless deploy
Ambiente prod:
serverless deploy —stage prod
Como resultado, se crearán dos buckets correspondientes a los entornos de desarrollo (dev) y producción (prod). En este caso, hemos configurado custom.stage para que dev sea el ambiente predeterminado, por lo que no fue necesario indicar explícitamente el stage en el primer comando.

En los próximos artículos, nos enfocaremos en el despliegue de permisos y funciones. Por lo tanto, es importante prestar atención a la línea de service. Además del nombre de nuestro proyecto, contiene la palabra infra para referenciar el nombre del bucket. Un valor que será agregado automáticamente por CloudFormation es el stage, por lo que encontraremos un bucket con el siguiente nombre después de realizar nuestro despliegue: nombre-de-mi-proyecto-infra-dev o nombre-de-mi-proyecto-infra-prod.
No debemos preocuparnos por el soft limit de los buckets (100) siempre que necesitemos más buckets, podremos enviar un ticket a AWS para incrementar dicho límite sin incrementar el valor de la factura, debido a que el cobro en S3 no es por la cantidad de buckets creados o disponibles.
El código mostrado en este artículo podrá ser descargado en este siguiente repositorio.
Mediante los pasos detallados en este artículo, hemos logrado desplegar una infraestructura en Amazon Web Service (AWS). Es importante destacar que cada recurso y servicio dentro de esta plataforma tiene su propio esquema para ser creado. En futuros escritos, profundizaré en estos esquemas y sus aplicaciones para proporcionar un entendimiento más completo de cómo aprovechar al máximo los recursos de AWS.
Listopro Community da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.