De Web Scraping a Automatización con Python


Actualmente, la automatización de procesos digitales ha tenido un gran auge dentro de las empresas, debido a que éstos mejoran la productividad en sus diferentes departamentos. Gracias a su contribución con dejar de lado tareas repetitivas y ayudar al personal a centrarse en actividades que aporten valor al negocio, a estos procesos los conocemos como RPA (Robotic Process Automation).
Dichas actividades pueden ir desde tareas sencillas como realizar un clic, rellenar formularios o iniciar sesión dentro de una aplicación, hasta extraer, limpiar y manipular información, entre otras.
Al proceso o técnica de extracción de información dentro de un sitio web se denomina Web Scraping, mientras que al software o programa para scrapear lo llaman bot o spider. Esta técnica es utilizada por muchos negocios para obtener información valiosa, sea para monitorear a la competencia, optimizar precios o generar una base de datos para realizar, posteriormente, un modelo de Machine Learning.
Hoy en día, existen múltiples herramientas de automatización que incluyen la opción de Web Scraping. Entre ellas figuran Power Automate, UiPath y Blueprism, las cuales realizan tanto procesos simples como otros más complejos. Una de las desventajas cuando apenas se aprende sobre automatización de procesos con estas herramientas, es que el utilizarlas durante un largo periodo ó implementar ciertos componentes, requieren de una licencia.
Sin embargo, para realizar Web Scraping o procesos de automatización no es necesaria una herramienta especializada, sino que podemos hacerlo mediante código.
Entre los lenguajes de programación con bibliotecas especializadas en Web Scraping está Python, cuyo alto nivel ha estado muy sonado últimamente debido a que cuenta con bibliotecas de códigos reutilizables que permiten generar código para múltiples propósitos, además de que su sintaxis es muy intuitiva y fácil, en comparación con otros lenguajes.
Entre estas bibliotecas se encuentra Beautiful Soup, la cual extrae datos de archivos HTML y XML. También está Selenium, una paquetería que facilita el acceso a todas las funcionalidades de Selenium Web Driver e interactuar con los componentes dentro del servidor de la página requerida.
¿Cuáles herramientas se necesitan para iniciarse en Web Scraping?
- Un IDE que soporte Python. En este tutorial, utilizaremos VS Code.
- Instalación de Beautiful Soup 4 y requests.
Ahora sí, comencemos: Parte 1
Si bien se puede utilizar también Anaconda Navigator o Google Colab, en este caso utilizaremos una libreta en VS Code.
- Si aún no tienes habilitado Python dentro de tu IDE, puedes instalar la extensión dentro de la opción de extensiones en VS Code. Posteriormente instalaremos la de Jupyter notebook.

2. Generaremos un nuevo archivo del tipo Jupyter notebook.

3. Para la instalación de las librerías dentro de la terminal escribiremos lo siguiente:


4. Ahora importaremos las bibliotecas instaladas:
5. Para este ejemplo, utilizaremos un enlace dedicado a scrapear http://books.toscrape.com/ , tomado de la página toScrape.
Una vez que tenemos la url, generaremos la request del tipo get al servidor de la página con la librería requests, posteriormente generamos nuestro objeto soup, pasándole de parámetros el contenido de la request y el tipo de documento ya sea HTML o XML.

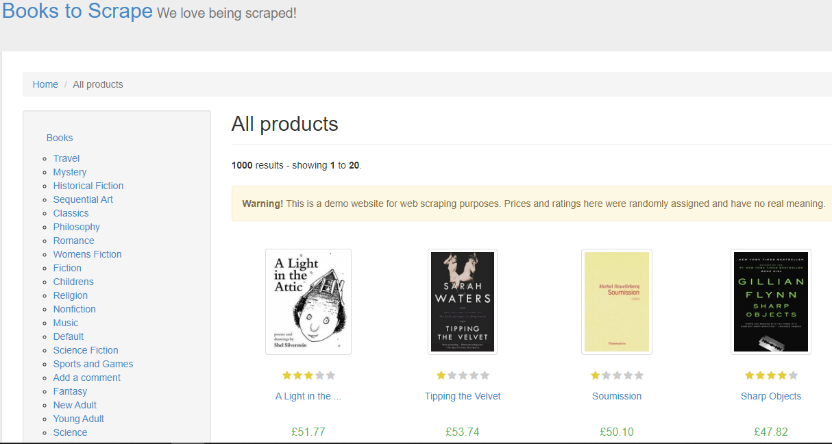
6. Vamos a nuestro navegador a la página y la analizamos.
Dentro de ella vemos que tenemos libros con diferentes categorías. Hay un total de 1000 libros, distribuidos de 20 libros por página con un total de 50 páginas.
7. Ahora presionamos botón derecho del mouse, damos clic en Inspect y buscamos la etiqueta que contenga los libros. Si presionamos en el teclado CTRL+SHIFT+C sobre los libros, éste nos mostrará la etiqueta donde se encuentran.

- Vemos que la etiqueta es de tipo section. Por lo tanto, regresamos a nuestra libreta y buscamos esa etiqueta.
- Para buscar la etiqueta <section></section> y traernos todo lo que contiene, utilizamos el método find(), el cual busca dentro de nuestro objeto soup la primera etiqueta con ese nombre y sus descendientes.

8. A continuación, extraeremos el nombre de todos los libros. Para ello, volvemos a nuestro navegador y vemos dentro de cuál tag se encuentra.
- Al ingresar dentro del tag section, observamos que todos los libros se encuentran en forma de lista ordenada dentro de nuestra etiqueta <ol>. Por ende, ahora sabemos que debemos extraer todas las etiquetas <li> y de ellas sacar el nombre de cada libro.
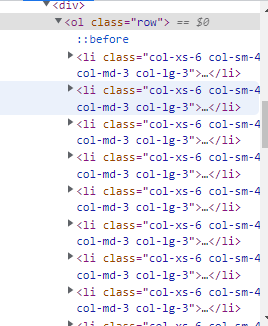
- Posteriormente, analizamos nuestros tags <li> y vemos que todos tienen una estructura similar. Éste tiene como descendiente un tag <article> y dentro de él tenemos 4 tags más los cuáles contienen:
- Un tag del tipo <div> con la imagen.
- Tag <p> con la calificación del libro.
- Un título <h3> con el nombre del libro.
- Un <div> con el precio.

- Al analizar el tag <h3>, notamos que dentro de él tenemos un tag <a> con 2 atributos href: link hacia el libro, y title, mismo que contiene el nombre completo del libro, lo que nos interesa extraer.
- Una vez conocido el camino para extraer el dato requerido, generamos el código.
9. Para extraer los elementos de lista <li> a nuestro objeto section que habíamos generado, implementamos el método findAll(), el cual reúne todos los elementos que encuentre con ese mismo tipo tag.

10. Ahora recorreremos nuestro objeto lis(una lista) y extraeremos los nombres de los libros. Para esto, dentro de un ciclo for (para recorrerla), usaremos el tamaño de la lista. El código funciona de la siguiente manera:
- Al obtener el len de la lista obtendríamos que es de 20.
- Si no especificamos desde dónde empieza la función range, toma como default el elemento 0.
- El ciclo for recorrerá desde el elemento 0 hasta el 19. Así, tendríamos 20 elementos.
- Obtenemos el elemento n de nuestra lista y, en su interior, buscamos el descendiente llamado <article>. Una vez dentro del tag <article>, vamos hacia el tag <h3> y el <a> tomando como valor el atributo title y lo imprimimos.
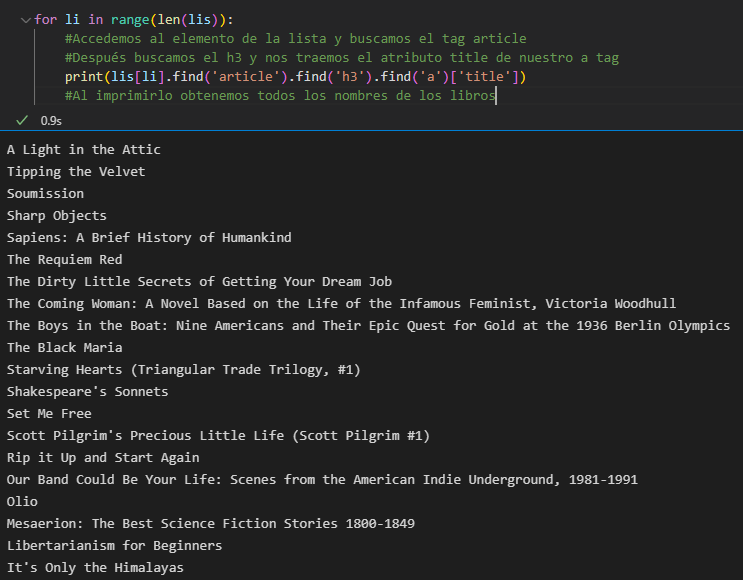
- Al contar los elementos impresos, notaremos que son los 20 nombres de los libros. Posteriormente, ingresamos estos valores dentro de una lista con el método append() y así quedaría nuestro código final:

- Al ejecutar la celda tendremos nuestra lista de títulos de libros.
11. Una vez realizado lo anterior, ya es más fácil obtener los demás componentes del libro, como el precio, calificación, etc.
¿Qué pasaría si en vez de traernos todos los libros, nos traemos los libros que solo pertenecen a la categoría “Travel”?
En este caso, podríamos obtener la url de esa categoría de forma similar a cómo nos trajimos el nombre del libro, pero al realizar este paso corremos el riesgo de que en algún punto cambie el formato o estilo del documento HTML. Lo mejor sería buscar el nombre de la categoría y darle clic, ¿no? Para realizar estas interacciones, es necesario utilizar Selenium WebDriver, el cual es un entorno de pruebas en la web.
Parte 2
A partir de aquí, realizaremos más procesos de automatización. Comenzaremos con un simple “clic”.
- Dentro de la terminal de nuestro proyecto, instalamos lo siguiente:

2. Es necesario instalar el web driver del navegador que se utilizará. En esta ocasión, instalaremos el web driver para Chrome. Para saber la versión de nuestro navegador:
I. Abre el navegador Chrome.
II. Da clic a los 3 puntos que aparecen arriba del lado derecho.
III. Clic en Ajustes.
IV. Dentro de Ajustes, selecciona About Chrome. Una vez ahí, veremos lo siguiente:

3. Ahora que conocemos nuestra versión, vamos a la página de Chromedriver y descargamos la correspondiente.
Una vez extraído el archivo .zip, ingresamos nuestro driver en la carpeta de nuestro proyecto.
4. Ahora regresamos a nuestra libreta:
I. Importamos Selenium webdriver.
II. Generamos nuestro sistema de pruebas o, más bien, declaramos nuestro web driver.
III. Maximizamos la pantalla y cargamos la página. Esto se realiza como buena práctica ya que cuando manejamos páginas responsivas puede llegar a cambiar el código de la página, por lo tanto al maximizarla de inicio mantenemos la fuente original.

IV. Al cargar la página al web driver, visualizaremos exactamente la página que le pasamos. Así parece, pero en realidad lo que obtenemos es una copia del servidor en nuestro entorno de pruebas.

En este entorno de pruebas podemos generar interacciones al servidor cómo si las estuviéramos ingresando de forma manual ya sean entradas a teclado o mouse implementando solo unas líneas de código.
5. Antes de pensar que ya perdimos todo el avance del código anterior, regresamos a nuestro notebook y nuevamente generamos nuestro objeto soup, pero ahora pasando el driver como parámetro.
De esta forma, si añadimos las líneas del código anterior después de la generación de soup, el código funcionará de la misma manera.

6. Ahora sí. Para hacer clic, utilizaremos el método find_element_by_link_text(), el cual busca el texto dentro del entorno y da opciones, dependiendo del tipo.
- Buscamos nuestra categoría Travel utilizando el método find_element_by_text() y damos clic:

- El motivo por el cual buscamos directamente el texto es porque hay múltiples elementos con el mismo tag, por lo tanto el buscar la categoría desde el inicio hace que nuestro proceso sea más rápido y limpio.
- Otra ventaja es que cuando realizamos Web Scraping debemos considerar que las páginas se actualizan y podrían llegar a cambiar su código fuente, por lo tanto es importante programar el bot pensando en estos posibles futuros cambios y mitigarlos, por que aunque cambie el código fuente, el nombre de la categoría no cambiará.
- Vamos a nuestro entorno y vemos qué ocurrió.

¡Nos encontramos dentro de la categoría Travel!
Con este sencillo ejemplo, hemos comenzado a scrapear la web. Bastante fácil, ¿verdad? Además de lo anterior, implementamos interacciones con nuestro navegador.
En próximas publicaciones veremos más métodos para sacarle provecho a Selenium, desde iniciar sesión, navegar entre páginas anidadas, seleccionar dropdowns, rellenar formularios y muchos otros.
Hasta pronto.
Revelo Content Network da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.