Data skills con KNIME - Parte 1


En esta serie, Desarrollando Data skills con KNIME, recorreremos diferentes desafíos con sus soluciones relacionadas a casos de uso básicos, medios y complejos. Estos desafíos, creados por miembros de la comunidad y del staff del software con el objetivo de ayudarnos a desarrollar más y mejores habilidades de análisis, forman parte de la primera temporada de los “Just KNIME It! Challenges” - 2022.
Para ello, utilizaremos KNIME Analytics Platform, un software open source creado bajo el paradigma de No code/Low Code, tema que desarrollaremos en futuros artículos con un enfoque orientado a datos. Esta plataforma permite a los usuarios consultar, transformar, analizar y visualizar datos con prácticamente poco y nada de código o bien con conocimientos básicos.
Con una curva de aprendizaje rápida, esta plataforma ofrece soluciones simples a usuarios principiantes y un conjunto de herramientas de ciencias de datos avanzadas a usuarios experimentados. Los flujos son realizados por medio de acciones drag & drop o arrastrar y soltar, conectando los nodos entre sí para producir los resultados intermedios y finales. ¡Manos a la obra!
El desafío
Para esta primera parte, el reto (nivel medio) considera crear un flujo que permita visualizar un conjunto de imágenes y que, de forma interactiva, pudiésemos seleccionarlo, filtrarlo o excluirlo. En este caso, utilizaremos un conjunto de imágenes aleatorias de Los Simpson, aunque puedes reemplazar las imágenes con aquéllas de tu interés.
Workflow o flujo de trabajo
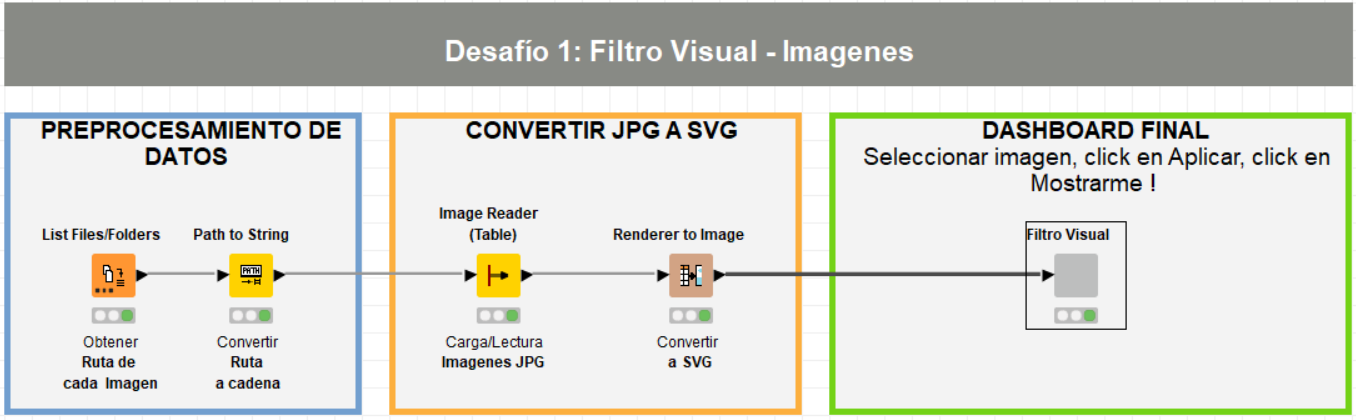
El primer paso requiere leer ese conjunto de imágenes desde un directorio. No necesitamos que sean imágenes de la misma dimensión o tamaño, pero sí es recomendable que sean imágenes de tipo JPG.
Configuramos el primer nodo de lectura dirigiéndolo al directorio donde alojamos las imágenes para recuperar/listar la ruta de cada una y luego, convertimos esa ruta a formato cadena.
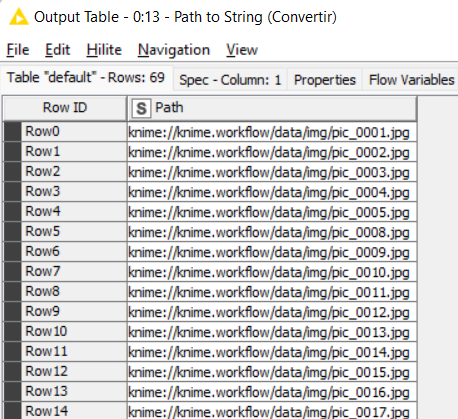
El resultado es una tabla donde en cada registro tenemos la dirección o ruta a cada imagen.
El siguiente paso es obtener propiamente la imagen y cargarla en la plataforma, de manera a que podamos visualizarla. Para renderizar las imágenes en una tabla dinámica, primero debemos convertirlas a formato SVG (Scalable Vector Graphics - formato de archivo vectorial apto para la web).

El resultado de la conversión es nuevamente una tabla con las imágenes listas para ser puestas en una tabla dinámica.

El último paso del flujo consiste en el desarrollo de un componente que nos brindará la funcionalidad de crear dashboards o tableros analíticos. Para ello, encapsulamos dos tablas dinámicas (Tile View o Mosaicos), un filtro y un botón de Mostar resultados, además de otros nodos que nos mostrarán los títulos y subtítulos:

En la siguiente imagen, podemos observar la composición interna del componente:

Al abrir o desplegar el nodo, en la ventana de visualizaciones seleccionamos manualmente aquellas imágenes en donde no aparece Marge Simpson y las filtramos, de manera a que únicamente queden las imágenes donde sí aparece y luego hacemos click en el botón Apply (parte inferior), que aplicará el filtro dinámico.
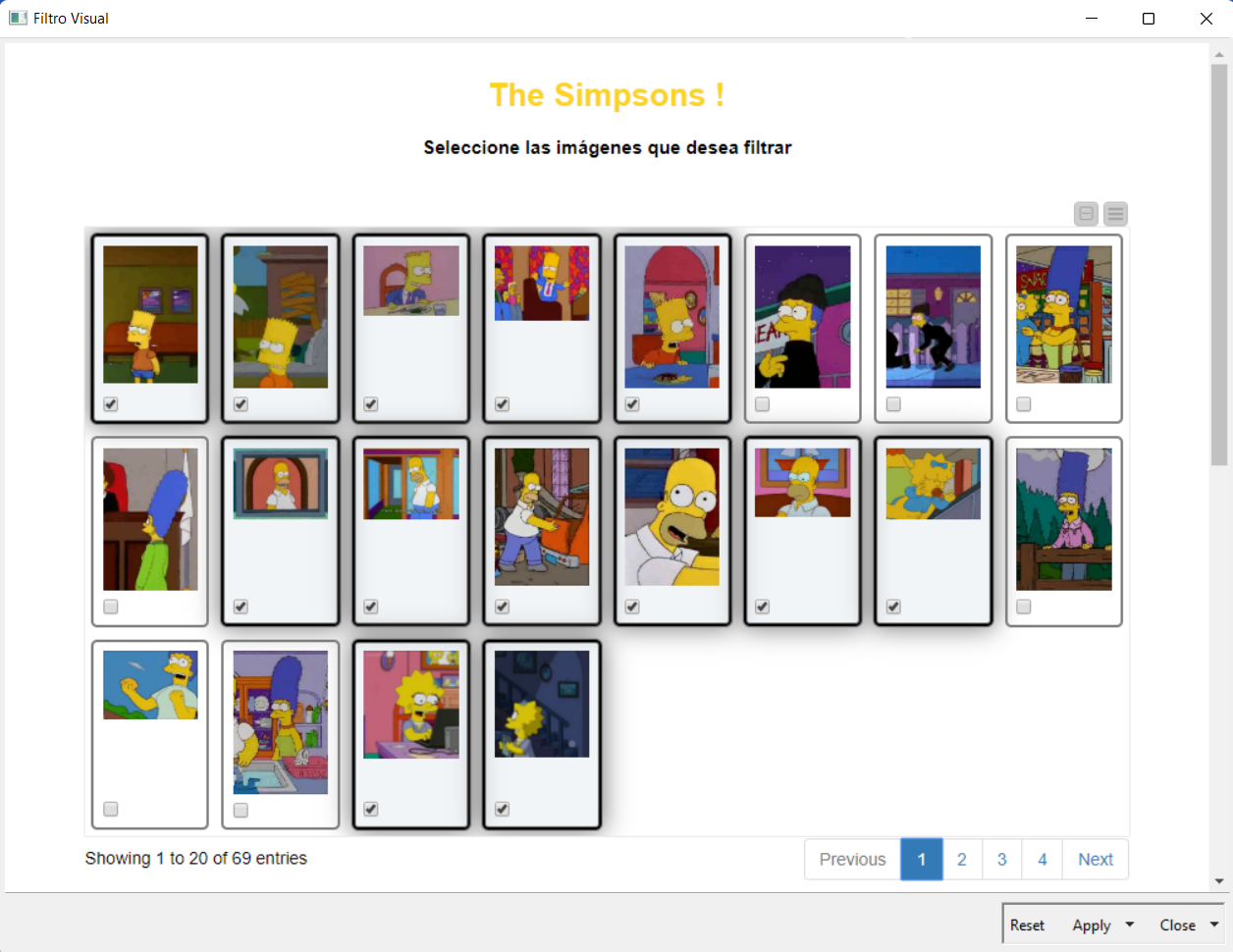
Finalmente, el último paso hacer click en el botón amarillo ¡Muéstrame!, que actualizará la segunda tabla dinámica y mostrará únicamente las imágenes que no fueron seleccionadas en el paso anterior.

El flujo completo es el siguiente:
Como pueden notar, ¡ni una sola línea de código! En cuatro pasos creamos un simple flujo de lectura, procesamiento y visualización de imágenes.
¿Qué aprendimos con este desafío?
Utilizando los nodos List Files/Folders, Path to String, Image Reader (Table) y Renderer to Image aprendimos a cargar imágenes al espacio de trabajo, previamente leyendo la ruta de ubicaciones de cada una de ellas, a renderizarlas o convertirlas a otro formato (SVG) y, finalmente, con el Component, creamos un simple visualizador en mosaico para aplicar los filtros sobre las imágenes.
El nodo List Files/Folders no es únicamente para leer rutas de imágenes, sino de cualquier formato de archivo soportado por la plataforma (TXT, CSV, XLSX, JPG, etc.), para luego manipularlo.
El Component es una colección o agrupación de nodos que nos permite agrupar subtareas (simplificar nodos en el workflow principal) o bien crear tableros analíticos. En próximas ediciones, veremos aplicaciones más complejas de los componentes.
Casos de uso
En su mayoría, los flujos de trabajos relacionados a análisis de imágenes son desarrollados para procesarlas y obtener más información, clasificar, corregir o segmentar imágenes, determinar patrones o identificar objetos específicos de interés. Los más clásicos ejemplos son aquellos dentro del área de Computer Vision, normalmente aplicada al análisis de imágenes médicas, en donde se utilizan algoritmos complejos de Redes Neuronales para analizar patrones y determinar posibles casos positivos de cáncer en pacientes, así como también, el análisis en tiempo real de video feeds.
Otros ejemplos prácticos relacionados
En este enlace al KNIME Hub (Portal de soluciones y espacios colaborativos), encontrarán de manera pública (en inglés) la versión original de esta solución al desafío.
Otro ejemplo más complejo utilizando el concepto de selección de imágenes en mosaico es el siguiente; en donde se puede descomponer una imagen en sus colores dominantes utilizando el servicio Google Cloud Vision API.
Conclusión
Este es el primer artículo de una serie de 40 desafíos con soluciones, en donde exploraremos diferentes habilidades de análisis de datos de diversos tipos, pasando por mejores prácticas de visualizaciones de datos, manipulaciones de archivos y conceptos básicos de minería de datos.
Como adelanto, en el próximo artículo veremos cómo manipular archivos leyendo un archivo general y particionándolo en archivos específicos por Año y Mes en diferentes directorios.
Sin importar tu background profesional, esta es una excelente oportunidad de conocer una plataforma que te ayudará a analizar información del día a día.
Revelo Content Network da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.