Visualización de datos con Dash Framework: Proceso ETL y uso de Python, Ploty Dash y MongoDB


En el presente artículo desarrollaremos un dashboard que consume data almacenada en una base de datos no relacional MongoDB que ha sido alimentada a través de archivos CSV usando Python.
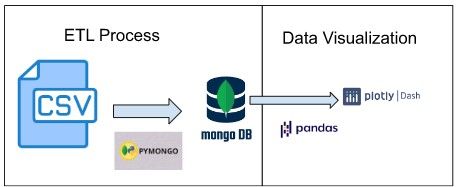
Para abarcar este proyecto, se ha dividido su estructura de la siguiente manera:
- ETL Process.
- Data Visualization.
¿Qué es un ETL process?
El proceso ETL es un proceso de integración de datos inteligente que consta de tres fases: extracción (extract), transformación (transform) y carga (load).
Fase de extracción
En esta fase se realiza el siguiente proceso:
- Extraer datos desde el archivo CSV.
- Analizar los datos e interpretarlos, verificando cuáles datos son importantes y cuáles son rechazados.
- Los datos considerados importantes pasan al proceso de transformación.
- Eliminación de anomalías respecto a la media.
Fase de transformación
En esta fase se realiza la limpieza de datos y el cálculo de más campos. Entre las actividades comunes se tienen:
- Calcular campos tal como la edad, a partir de la fecha de nacimiento, margen de utilidad restando los ingresos y gastos, entre otros.
- Limpiar la información, tal como eliminación de los espacios vacíos.
- Conversión de valores categóricos y valores numéricos.
- Normalización de la data, para que toda la data tenga un mismo estándar.
Fase de carga
Es el proceso de cargar los datos transformados. Esta fase interactúa directamente con la base de datos de destino, aplicando restricciones para garantizar la calidad de los datos.
Existen dos formas de desarrollar proceso de carga:
- Rolling: Se almacena información resumida, por lo general los totales o cuartiles.
- Acumulación: Se carga resumen de las transacciones comprendidas en un tiempo seleccionado.
¿Qué es MongoDB?
Es una base de datos denominada No-SQL, por lo que no tiene una estructura de bases de datos tradicional entidad-relación. MongoDB usa documentos JSON con esquemas dinámicos, alternando el esquema de acuerdo con la necesidad de los datos.
¿Qué es un Ploty Dash?
Es una librería de interfaz desarrollada en Plotly.js y React, que permite construir y desplegar aplicaciones de análisis de datos. Dash se abstrae de la tecnología y del protocolo construidos a través del modelo vista controlador de un entorno Web, haciendo la programación enfocada en la visualización. Las aplicaciones Dash son renderizadas en el navegador web, incluso pueden ser instaladas en una máquina virtual y luego se comparten a través de la URL.
Instalación y configuración de MongoDB
Lo más recomendable es usar los repositorios oficiales de Ubuntu que incluyen una versión estable de MongoDB.
Para empezar, se debe importar la clave pública para la última versión estable de MongoDB, aplicando lo siguiente:
wget -qO - https://www.mongodb.org/static/pgp/server-6.0.asc | sudo apt-key add -
Actualizamos Ubuntu con la clave pública importada.
sudo apt-get update
Procedemos a instalar MongoDB.
sudo apt-get install -y mongodb-org
Levantamos el servicio MongoDB.
sudo systemctl start mongod
Reiniciamos el daemon de Ubuntu.
sudo systemctl daemon-reload
Verificamos el estado de MongoDB.
sudo systemctl status mongod
Habilitamos el servicio de MongoDB.
sudo systemctl enable mongod
Para comenzar a usar MongoDB, ejecutamos mongosh.
mongosh
Configuración de ambiente virtual
En una carpeta dentro del directorio de Ubuntu, creamos un ambiente virtual de Python con la siguiente configuración:
sudo apt-get install -y python3-venv
python3 -m venv venv
source venv/bin/activate
Para saber que se encuentra dentro del entorno virtual, verificamos que aparezca (venv) como prefijo a la máquina:
(venv) kleber@legion:~/dashboard_open$
Dentro del ambiente virtual, instalamos los paquetes necesarios, tales como:
pip install pymongo==3.12.3
Aunque exista una versión más actualizada, les recomiendo usar 3.12.3, para evitar el siguiente error:
NotImplementedError: Database objects do not implement truth value testing or bool(). Please compare with None instead: database is not None
Posteriormente, instalamos los siguientes paquetes dentro del ambiente virtual:
pip install dnspython
pip install numpy
pip install pandas
pip install python-dateutil
pip install pytz
pip install six
Se recomienda crear un archivo con los paquetes instalados dentro del entorno virtual para que en una posible migración de equipo se pueda tener el mismo entorno. Es muy recomendable tener el mismo entorno en ambiente de desarrollo y producción.
Configuración IDE
Se recomienda usar Visual Studio Code y seguir las instrucciones de este enlace para que se adapte a las necesidades del proyecto.
Instalación y configuración de Dash
En el mismo entorno virtual instalar las siguientes librerías para configurar el entorno de Dash.
pip install dash
Al instalar Dash viene incorporada la librería gráfica Plotly. Posteriormente, se instala Pandas para el manejo del cálculo de los datos.
pip install pandas
ETL Process
Fase de extracción: Cargar información CSV
En la carpeta principal se crea un archivo Python:
touch ETL_process.py
Se procede con la importación de librerías.
- Pymongo es una librería que permite interactuar con la base de datos MongoDB.
- Pandas es una librería que permite cargar el archivo csv e interactuar con dataframes.
- Json es una librería que permite transformar los dataframes en formato Json.
Fase de transformación
En esta fase se realizan procesos de clasificación y conteo que son las transformaciones de los datos.
Clasificación de la data por su variedad
Para clasificar la información, se debe analizar cada columna o, dicho de otra manera, cada variable del conjunto de datos. Luego de analizar la data (a través del archivo csv por separado) se observa que la variable ‘variety’ está clasificada en tres clases, por lo que se la clasifica de dicha manera:
setosa_data=iris_dat[(iris_dat['variety'] == 'Setosa')]
versicolor_data=iris_dat[(iris_dat['variety'] == 'Versicolor')]
virginica_data=iris_dat[(iris_dat['variety'] == 'Virginica')]
Otro rubro importante son las cantidades de cada clase dentro del conjunto de datos. Se calcula la longitud de cada arreglo.
cant_setosa=len(versicolor_datlen(setosa_data)
cant_versicolor=len(versicolor_data)
cant_virginica=len(virginica_data)
cant_tot_variedad = [cant_setosa, cant_versicolor, cant_virginica]
label_variedad =[Setosa','Versicolor','Virginica']
df_cant_variedad = pd.DataFrame(cant_tot_variedad,index=label_variedad,
columns =['Variedad'])
Los totales de cada clase se transforman en un dataframe, incorporando una lista de labels, como se detalla en la porción de código con la variable ‘label_variedad’.
Fase de carga (loading)
En esta fase, se procede a cargar los dataframes generados en la fase de transformación en colecciones de MongoDB.
setosa_coll = json.loads(setosa_data.T.to_json()).values()
db.setosa.insert(setosa_coll)
versicolor_coll = json.loads(versicolor_data.T.to_json()).values()
db.versicolor.insert(versicolor_coll)
virginica_coll = json.loads(virginica_data.T.to_json()).values()
db.virginica.insert(virginica_coll)
cant_variedad_coll = json.loads(df_cant_variedad.to_json()).values()
db.cant_variedad.insert(cant_variedad_coll)
Comprobar que las colecciones han sido guardadas en MongoDB. Se comprueba que se ha creado la base de datos:
test> show dbs
db_iris 32.00 KiB
Y las colecciones:
test> use db_iris
switched tcollectionso db db_iris
db_iris> show collections
cant_variedad
setosa
versicolor
virginica
Se visualiza que hay un total de cuatro colecciones, las tres respecto a las clases y cant_variedad, que se refiere a los totales de registros por cada clase. Para consultar el contenido de una colección, aplicar:
dbiris> db.cantvariedad.find();
[
{
id: ObjectId("63ad39af34e57403210047b9"),
Setosa: 50,
Versicolor: 50,
Virginica: 50
}
]
Visualización de datos
Crear un archivo Python en el directorio principal:
touch dashboard.py
Importación de datos desde MongoDB
Importar las librerías Pymongo y Pandas, para acceder y operar los datos respectivamente.
import pandas as pd
from pymongo import MongoClient
Conexión con MongoDB para extraer los dataframes de sus colecciones.
mongClient = MongoClient('127.0.0.1', 27017)
db = mongClient.db_iris
setosa_df = pd.DataFrame(list(db.setosa.find()))
versicolor_df = pd.DataFrame(list(db.versicolor.find()))
virginica_df = pd.DataFrame(list(db.virginica.find()))
cant_variedad_df = pd.DataFrame(list(db.cant_variedad.find()))
Probar en Jupyter Notebook, que ha extraído los documentos de MongoDB con alguna variable:
_id Setosa Versicolor Virginica
0 63b0e2ff029958f05d92ce23 50 50 50
Creación del Dashboard
Importar librerías
from dash import Dash, html, dcc, Input, Output, dash_table
import dash_bootstrap_components as dbc
Descripción de las librerías importadas
Dash: La librería Dash permite hacer el deployment en Flask; su componente más usado es el layout, donde se aloja los componentes Html, CSS y JavaScript.
Html: Es el módulo para crear componentes Html, tales como div, body, p, a, entre otros.
Dcc: Es el módulo de componentes principales de Dash (Dash Core Components), otorga acceso a los componentes interactivos como dropbox, sliders, radio button, entre otros.
Input: Alberga los componentes de entrada de un método callback que se aplican a un Dcc.
Output: Alberga los componentes de salida de un método callback que se aplican a un Dcc.
Dash_table: Es el módulo que permite crear tablas de datos. Su comportamiento es personalizable a través de sus propiedades, las tablas de datos son renderizadas.
Dbc: Es una librería de componentes de bootstrap en el framework Dash, que permite construir más fácil las app agregando responsive.
Creación de la barra de navegación
logo = 'https://i.pinimg.com/originals/a3/66/f0/a366f0985b6d2750b0242b66fbdef604.png'
navbar = dbc.NavbarSimple(
brand='Iris Dashboard',
brandstyle={'fontSize': 40, 'color': 'white'},
children=
[
html.A(
html.Img(src=logo, width='100',height='40'),
href='https://archive.ics.uci.edu/ml/datasets/iris',
target='_blank',
style={'color': 'black'}
)
],
color='primary',
fluid=True,
sticky='top'
)
El enlace del logo, es una imagen abierta. La librería dbc llama su componente NavbarSimple para crear un barra de navegación simple, personalizando color, tamaño de letra y sus componentes hijos. Tal como se aprecia en la imagen.

Deployment
Para desplegar la aplicación, se ejecuta la variable app del componente Dash con su método run_server.
app = Dash(external_stylesheets=[dbc.themes.BOOTSTRAP])
app.layout = html.Div([navbar,])
if name == 'main':
app.run_server(debug=True)
Para agregar responsive a la aplicación, se agrega el tema BOOTSTRAP a través de su componente dbc.BOOTSTRAP. Al ejecutar el archivo Python debe mostrar lo siguiente:
(venv) kleber@legion:~/dashboard_open$ python dashboard.py
Dash is running on http://127.0.0.1:8050/
* Serving Flask app 'dashboard'
* Debug mode: on
La aplicación se está ejecutando de manera local:
- Host: 127.0.0.1
- puerto: 8050
- servidor: Flask
La aplicación se mostraría en el navegador:

Componentes en Dash
Pastel de los totales
Para agregar la gráfica de pasteles en Dash, se procede a importar el componente graph_objects de la librería Plotly.
import plotly.graph_objects as go
pie_variedad_totales = go.Figure(
data= [
go.Pie(labels=cant_variedad_df.T.index[1:4].tolist(),
values=cant_variedad_df.T[0].values[1:4].tolist())
],
layout= {
"title": "Variedad Iris",
"height": 390, # px
"width": 390,
},
)
Luego se usa el componente graph_object para crear un gráfico pastel, tal como indica en el código. El componente además de usar los label y values, que son la data del dataframe, se agregan propiedades del gráfico, tal como título, altura y ancho. Para presentar el gráfico, se tiene se tiene que crear un componente dcc.Graph, que es un componente tipo gráfico. Finalmente, agregar el objeto gráfico pie_variedad_totales:
app.layout = html.Div([
navbar,
dcc.Graph(
id='Exports-vs-products',
figure=pie_variedad_totales
)
])
La salida en el Dashboard:
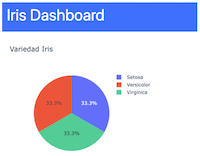
Tabla y gráfico lineal de los dataframe
En esta sección final se mostrará una tabla usando un método callback, para cambiar la información de las diferentes variedades de la planta iris. Se crea un componente dropdown para elegir el tipo de variedad:
drop_vary=dcc.Dropdown(id='drop_vary',options=cant_variedad_df.T.index[1:4].tolist())

Finalmente, se crea una tabla en conjunto con su gráfico para representar los datos de cada una de las clases de variedad del conjunto de datos de iris.
Comando para la creación de la tabla:
dash_table.DataTable(id='data-iris'),
Comando para la creación del gráfico de los datos:
dcc.Graph(id='graph-iris')
La tabla y el gráfico son componentes que se actualizan de acuerdo con la selección del usuario en el dropdown. Las opciones son las clases de variedad, tales como setosa, versicolor y virginica.
Para actualizar la tabla, aplicar lo siguiente:
@app.callback(
Output('data-iris', 'data'),
Input('drop_vary', 'value'),
)
def update_table(drop_vary):
if drop_vary=='setosa':
ta_re=setosa_df.filter(items=['sepal.length','petal.length']).head(5).to_dict('records')
elif drop_vary=='Versicolor':
ta_re=versicolor_df.filter(items=['sepal.length','petal.length']).head(5).to_dict('records')
elif drop_vary=='Virginica':
ta_re=virginica_df.filter(items=['sepal.length','petal.length']).head(5).to_dict('records')
else:
ta_re=setosa_df.filter(items=['sepal.length','petal.length']).head(5).to_dict('records')
return ta_re
Se convoca al decorator app.callback para actualizar los campos. El elemento de entrada drop_vary permite escoger la clase de variedad de iris. La salida es la tabla data-iris, que se actualiza según la clase de variedad. La función de actualización update_table recibe el id drop_vary del componente dropdown.
A través de if anidados se elige el dataframe para mostrar la data en la variable ta_re. Finalmente, se retorna la propiedad data, actualizando la tabla de datos.
Actualizar el gráfico
@app.callback(
Output('graph-iris', 'figure'),
Input('drop_vary', 'value'),
)
def update_chart(drop_vary):
if drop_vary=='setosa':
fig_len= px.scatter(setosa_df, x="sepal.length", y="petal.length")
elif drop_vary=='Versicolor':
fig_len= px.scatter(versicolor_df, x="sepal.length", y="petal.length")
elif drop_vary=='Virginica':
fig_len= px.scatter(virginica_df, x="sepal.length", y="petal.length")
else:
fig_len= px.scatter(setosa_df, x="sepal.length", y="petal.length")
return fig_len
Al igual que en la tabla se llama al decorator para indicar entrada y salida de los componentes. En conjunto con la función de actualización update_chart se escoge los datos del gráfico a retornar en la variable graph-iris. La salida del código:
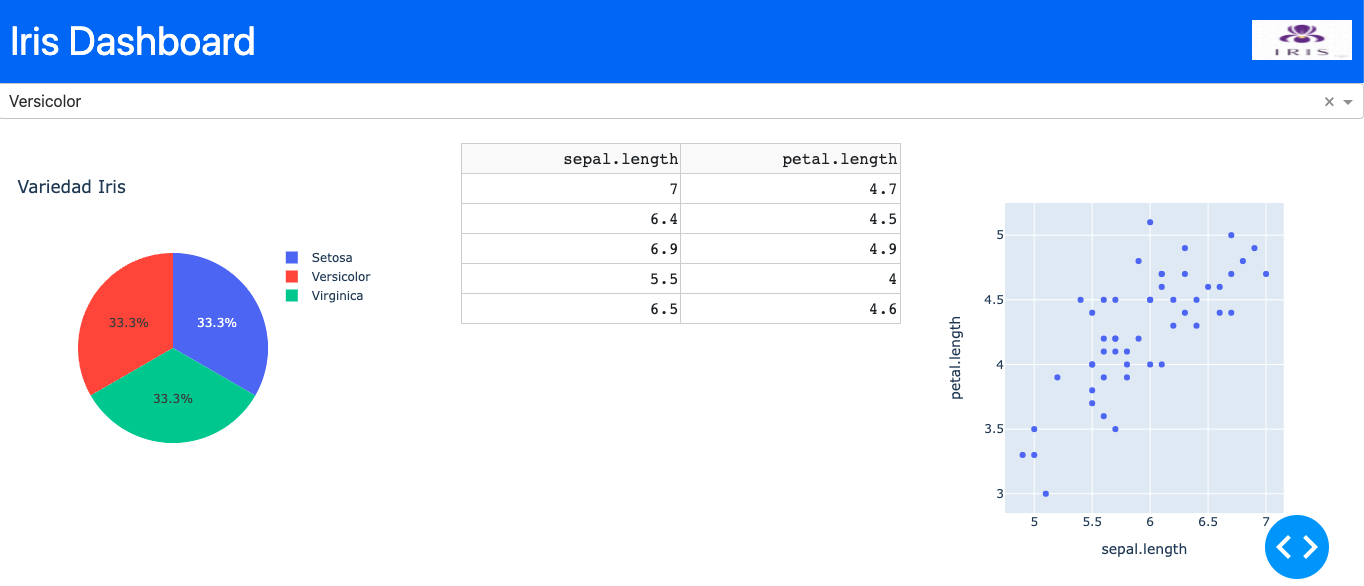
En la gráfica se ha escogido la clase de variedad versicolor, mostrando en la tabla la longitud de sepal y petal, a un costado la gráfica con el total de los puntos. La tabla solo muestra los 5 primeros datos.
Concluyo que con este cookbook puedes arrancar en tu camino para realizar Dashboard usando herramientas absolutamente Open Source. Te recomiendo seguir canales oficiales de las herramientas como https://dash.plotly.com/ y https://www.mongodb.com/try/download/shell.
El código completo lo puedes clonar desde el repositorio GitHub de mi perfil.
Pronto publicaré más contenido sobre Data Science. Sígueme para mayor contenido similar.
¡Hasta luego!
Revelo Content Network da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.