Creando tu primer modelo de IA: Clasificación de mensajes Spam con Python


En la actualidad, el flujo constante de mensajes de correo electrónico y mensajes de texto ha hecho que la clasificación de mensajes spam sea una tarea esencial en nuestra vida digital. ¿Quién no ha recibido alguna vez un correo no deseado en su bandeja de entrada?
Afortunadamente, la Inteligencia Artificial (IA) y el Aprendizaje Automático (Machine Learning) nos ofrecen herramientas poderosas para abordar este problema. En este artículo, te guiaré a través de la creación de tu primer modelo de IA en Python para identificar y clasificar mensajes como spam o ham (no spam).

Conceptos Básicos de IA y Aprendizaje Automático
Antes de sumergirnos en la creación del modelo, es importante comprender algunos conceptos clave.
- La Inteligencia Artificial se centra en crear sistemas capaces de realizar tareas que requieren inteligencia humana, como el reconocimiento de patrones.
- El Aprendizaje Automático, por otro lado, es una rama de la IA que se enfoca en desarrollar algoritmos y modelos que pueden aprender de datos y tomar decisiones basadas en esos datos.
Obteniendo datos de ejemplo
Para construir nuestro modelo de IA, necesitamos datos de entrenamiento. Puedes crear tu propio conjunto de datos etiquetando manualmente mensajes como "spam" o "ham", o puedes utilizar un conjunto de datos público. En este ejemplo, utilizaremos un conjunto de datos de muestra que he preparado y que puedes encontrar en mi repositorio de GitHub.
Cargar datos con Pandas
Utilizaremos la biblioteca Pandas en Python para cargar los datos desde el archivo CSV. Asegúrate de tener Pandas instalado con anterioridad. Aquí está el código para cargar los datos y mostrar las primeras filas del DataFrame:

El DataFrame resultante contendrá dos columnas: una para las etiquetas ("label") que indican si el mensaje es spam o ham, y otra para el contenido del mensaje ("message"). Estos datos son esenciales para entrenar y evaluar nuestro modelo de IA de clasificación de mensajes spam.
Limpieza y Preprocesamiento de Datos
Una vez cargados nuestros datos, es importante realizar una limpieza y preprocesamiento adecuados antes de utilizarlos para entrenar nuestro modelo de IA. Esto implica realizar varias tareas, como:
- Conversión a Minúsculas: Esto para asegurarnos de que las letras mayúsculas y minúsculas no se traten como diferentes.
- Eliminación de Números: En muchos casos, los números no son relevantes para la clasificación de mensajes spam, por lo que es común eliminarlos.
- Eliminación de Signos de Puntuación: Los signos de puntuación generalmente no aportan información útil en este contexto, por lo que pueden ser eliminados.
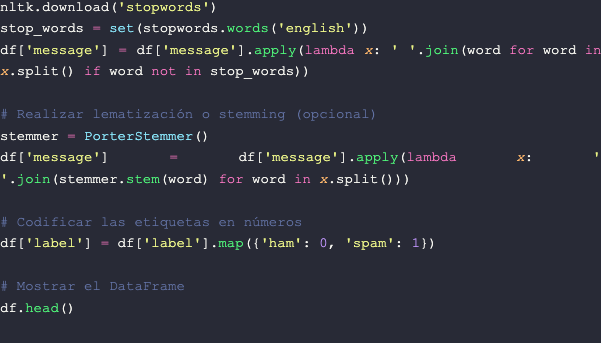
- Eliminación de Palabras Vacías (Stop Words): Las palabras comunes como "y", "el", "en", etc., generalmente no contribuyen con la clasificación y pueden eliminarse.
- Lematización o Stemming: Reducir las palabras a su forma base (lema) o a su raíz (stem) puede ayudar a reducir la dimensionalidad del texto y mejorar la precisión del modelo.
- Codificación de etiquetas: Para realizar el modelo, es necesario codificar las etiquetas en números. Podemos asignar el valor 0 para ham y 1 para spam.
Aquí hay un ejemplo de cómo podrías realizar algunas de estas tareas en Python utilizando la biblioteca NLTK. Asegúrate de tenerla instalada con anterioridad:

División de los datos en conjuntos de entrenamiento y validación
Una vez realizada la limpieza y preprocesamiento de nuestros datos, es fundamental dividirlos en conjuntos de entrenamiento y validación. Esto nos permitirá entrenar nuestro modelo de IA y evaluar su rendimiento de manera efectiva.
Utilizaremos la biblioteca Scikit-learn en Python para realizar esta división. Aquí está el código:

Tokenización de Texto y Padding de Secuencias
Cuando trabajamos con modelos de Procesamiento de Lenguaje Natural (NLP) en el contexto de la Inteligencia Artificial, es fundamental preparar los datos de texto de manera adecuada. Dos de los pasos esenciales en este proceso son la tokenización de texto y el padding de secuencias. A continuación, exploraremos estos conceptos y su importancia en la construcción de modelos de IA para el procesamiento de texto.
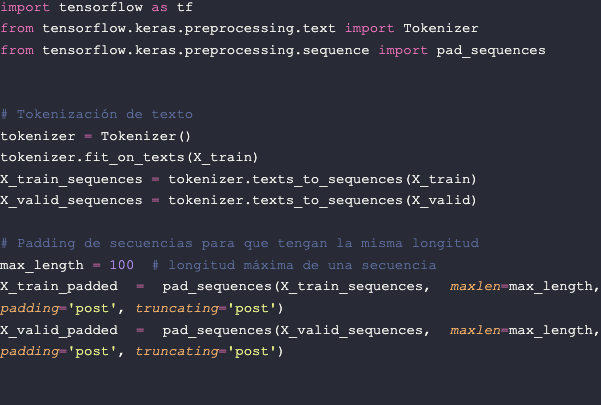
- Tokenización de Texto: es el proceso de dividir una secuencia de texto en unidades más pequeñas llamadas tokens, los cuales suelen ser palabras individuales. La tokenización es esencial porque permite que la máquina comprenda y procese el texto a nivel de unidades significativas. Supongamos que tenemos la siguiente oración: "La inteligencia artificial es fascinante". La tokenización de esta oración podría generar los siguientes tokens: ["La", "inteligencia", "artificial", "es", "fascinante"].
- Padding de Secuencias: Una característica importante de las redes neuronales es que requieren que los datos de entrada tengan dimensiones fijas. Sin embargo, las secuencias de texto suelen tener longitudes variables. Para abordar este desafío, utilizamos el Padding de Secuencias, que consiste en ajustar la longitud de todas las secuencias de texto para que tengan la misma longitud. Esto se logra agregando tokens de relleno (generalmente representados como ceros) al principio o al final de las secuencias más cortas. Esta uniformidad de longitud es esencial para que las redes neuronales procesen los datos de manera efectiva. Supongamos que tenemos dos oraciones: "El aprendizaje automático es emocionante" y "Redes neuronales". Si establecemos una longitud máxima de secuencia de 5 tokens, la primera oración se rellenaría con tokens de relleno al final para alcanzar la longitud deseada: ["El", "aprendizaje", "automático", "es", "emocionante"]. La segunda oración también se rellenaría de manera similar: ["Redes", "neuronales", 0, 0, 0].
Estos procesos de tokenización y padding nos permiten representar el texto de manera adecuada para su procesamiento por una red neuronal, garantizando que todas las secuencias tengan la misma longitud. Para realizar este proceso con Python utilizaremos la librería de TensorFlow:
Construcción y entrenamiento del modelo de IA
Ahora que hemos preparado nuestros datos y los hemos dividido en conjuntos de entrenamiento y validación, procederemos a construir y entrenar nuestro modelo de IA. En este caso, utilizaremos una Red Neuronal Recurrente (RNN, por sus siglas en inglés) para realizar la clasificación de mensajes en spam y ham.
1) Importación de Bibliotecas y Creación del Modelo: esencial para construir y entrenar nuestro modelo.

2) Sequential de TensorFlow: Crearemos un modelo de IA que se llama Sequential en TensorFlow, que permite construir capas una tras otra de manera sencilla.

3) Capa de Embedding: La capa de embedding se utiliza para convertir palabras en números. En otras palabras, ayuda al modelo a entender el significado de las palabras. vocab_size es la cantidad total de palabras únicas en nuestro conjunto de datos. embedding_dim es la cantidad de números que representarán cada palabra. Esta capa se encarga de convertir palabras en vectores de números.

4) Capa LSTM: Agregamos una capa LSTM (Long Short-Term Memory). Piensa en esta capa como una parte del modelo que puede recordar información importante de las secuencias de palabras. units=64 significa que esta capa tendrá 64 "neuronas" que pueden recordar información relevante.

5) Capa Densa: Agregamos una capa densa que se utiliza para hacer la clasificación final entre spam y ham. 1 significa que esta capa tiene una sola salida que se utiliza para la clasificación binaria. Utilizamos la función de activación sigmoide para que el modelo devuelva un valor entre 0 y 1, donde valores cercanos a 0 indican ham y valores cercanos a 1 indican spam.

6) Compilación del Modelo: Compilamos el modelo, lo que significa que estamos configurando cómo se entrenará. Usamos el optimizador adam, un algoritmo que ayuda al modelo a aprender de manera eficiente. De igual forma, empleamos la pérdida (loss) binary_crossentropy porque hacemos una clasificación binaria (dos clases: spam y ham). También usamos la precisión (accuracy) como una métrica para ver qué tan bien funciona el modelo.

7) Entrenamiento del modelo: Ahora entrenamos el modelo con nuestros datos de entrenamiento. Epochs es la cantidad de veces que el modelo verá todo nuestro conjunto de entrenamiento. X_train_padded son las secuencias de texto de entrenamiento con padding, y y_train son las etiquetas correspondientes (spam o ham). También evaluamos el modelo en nuestros datos de validación (conjunto de validación) para ver cómo se desempeña en datos que no ha visto durante el entrenamiento.

Prueba tu modelo
Ahora te mostraré cómo puedes usar el modelo entrenado para predecir si un mensaje es spam o no spam, proporcionando un mensaje en forma de cadena (string). Aquí tienes un código de ejemplo para hacerlo:
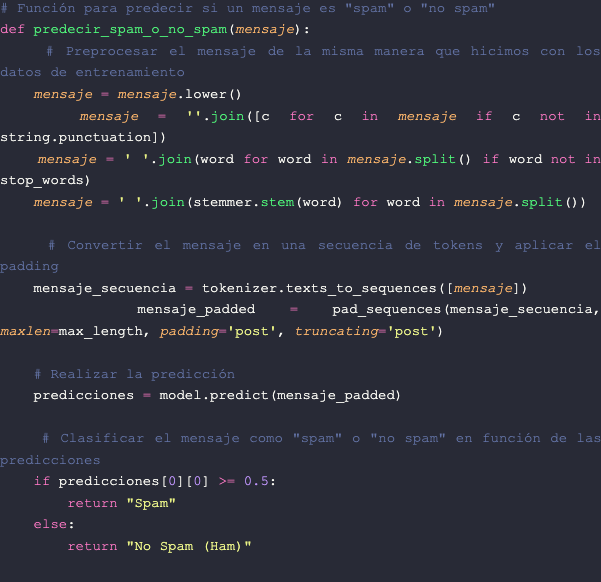
Hemos creado una función llamada predecir_spam_o_no_spam que toma un mensaje como entrada. Dentro de la función, preprocesamos el mensaje de la misma manera que lo hicimos con los datos de entrenamiento, convirtiéndolo en minúsculas, eliminando signos de puntuación, palabras vacías y aplicando lematización o stemming.
Luego, convertimos el mensaje en una secuencia de tokens y aplicamos el padding para que tenga la misma longitud que las secuencias de entrenamiento. Finalmente, utilizamos el modelo entrenado para hacer una predicción en el mensaje y clasificarlo como spam o ham en función de la predicción.
Es importante entender cómo interpretar las métricas de rendimiento de un modelo de clasificación de mensajes spam. Dos métricas comunes son la precisión (accuracy) y la pérdida (loss).
- La precisión indica la proporción de predicciones correctas en relación con el total de predicciones realizadas por el modelo. Un valor de precisión más alto generalmente indica un mejor rendimiento.
- La pérdida es una medida de cuán bien se ajustan las predicciones del modelo a las etiquetas reales en el conjunto de validación. Un valor de pérdida más bajo generalmente indica un mejor rendimiento.
Puedes usar esta función predecir_spam_o_no_spam para probar cualquier mensaje que desees y ver si el modelo lo clasifica correctamente. ¡Solo asegúrate de haber entrenado el modelo previamente como se explicó en pasos anteriores!


Conclusión
En resumen, hemos recorrido juntos los pasos clave para la creación de tu primer modelo de IA para clasificar mensajes spam, desde la obtención de datos de ejemplo hasta la construcción y entrenamiento del modelo. Sin embargo, es importante recordar que el rendimiento de tu modelo depende en gran medida de la calidad de los datos de entrenamiento y de la elección de hiperparámetros adecuados.
Cabe mencionar que, en la clasificación de spam, suele haber un desequilibrio significativo entre las clases spam y ham. Esto significa que hay muchas más instancias de ham que de spam. Abordar este desequilibrio es importante para evitar que el modelo se sesgue hacia la clase mayoritaria. Para hacerlo, se pueden utilizar técnicas como el remuestreo de la clase minoritaria (aumento de datos de spam) o el ajuste de las ponderaciones de clase durante el entrenamiento del modelo. Estas estrategias ayudan al modelo a aprender de manera equitativa de ambas clases y a mejorar su capacidad para identificar mensajes de spam.
Es importante mencionar que el modelo presentado en este artículo es un modelo básico diseñado con fines educativos. Aunque es un buen punto de partida, para un modelo más completo y efectivo en la clasificación de mensajes spam en un entorno de producción, es necesario realizar una preparación más exhaustiva de los datos, considerar técnicas avanzadas de procesamiento de lenguaje natural, y explorar diferentes arquitecturas de modelos. Además, se debe prestar una atención especial al manejo del desequilibrio de clases, ya que en aplicaciones reales, la detección precisa de mensajes de spam es esencial para la seguridad y la experiencia del usuario.
Así que, mientras te aventuras en el mundo de la IA y el aprendizaje automático, recuerda que la experimentación y la iteración son clave. ¡Sigue explorando, ajustando y mejorando tu modelo para obtener resultados aún más precisos en la clasificación de mensajes spam! Con dedicación y práctica, podrás construir modelos de IA cada vez más efectivos y útiles en diversas aplicaciones. ¡Buena suerte en tu viaje hacia la creación de Inteligencia Artificial!
Si quieres consultar el modelo realizado, puedes hacerlo aquí.
Listopro Community da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.