Hazle preguntas a tu PDF usando LangChain, LLaMA 2 y Python


Vivimos una época sorprendente. Los Large Language Models (LLMs) han empezado a copar las noticias relacionadas con la Inteligencia Artificial (IA), y esto promueve el incremento de las posibilidades de aplicaciones. Un ejemplo son los chats inteligentes como ChatGPT de OpenIA, que son grandes modelos de aprendizaje que entregan respuestas mediante el uso de bastos recursos disponibles en internet. Y, aunque, las respuestas no son siempre fiables, pueden ser de gran ayuda en múltiples áreas. Aun cuando las aplicaciones de los LLMs se usan como chats generales para hacer preguntas y recibir respuestas, también se pueden combinar, por ejemplo, interactuando con un fichero PDF.
En el mundo académico, es normal que cada científico tenga que leer varios artículos (papers) cada semana para mantenerse actualizado en su campo. Y, no sólo académicos, también, es aplicable a cualquier persona que cultive su curiosidad. ¿Acaso no sería conveniente tener un asistente que nos ayudará a encontrar los puntos claves de un artículo, que además nos proveyera de un resumen, una suerte de primera aproximación al texto, para así evitar leer un artículo que quizá no es lo que buscamos? Pues hoy, gracias a los LLMs, ya es posible.
En este artículo explicaré qué son los LLMs, en particular Llama 2, un LLM de código abierto generado por Meta (ex Facebook). Y la herramienta LangChain, que nos permite interactuar con este y otros modelos de manera fácil y amena.
Para los ejemplos usaremos Python debido a su facilidad de uso. Aunque LangChain cuenta con interfaces para varios lenguajes de programación.

Large Language Model
Entre los varios tipos de LLM que existen, hay uno que nos interesa: el que dado una secuencia de texto (por ejemplo, una pregunta) predice una o más palabras. Conocido como Decoder LLMs. Y, ChatGPT es uno de ellos, esto permite responder a nuestras preguntas tales como «¿Cuál es la mejor estrategia para aprender a programar?», o, simplemente, hacer algún comentario según un texto que escribamos, como puede ser un «¡Hola, ChatGPT!».
Al final, estas predicciones son generaciones de textos, y pertenece al tipo de herramientas de IA que se llaman: generativas. La calidad de un LLM se mide de acuerdo a su coherencia, exactitud y correcta contextualización de sus respuestas. Estas mediciones la realizan personas, de esta forma, se puede dar con sus fortalezas y debilidades.
LLaMA 2
Durante 2023, Meta anunció LLaMA 2 (desde ahora simplemente lo nombraré Llama 2), un LLM de código abierto que viene a ser la evolución de su modelo anterior (LLaMA 1), que puede ser usado para crear aplicaciones con fines comerciales.
Las instrucciones para descargarlo se encuentran en su repositorio:
 facebookresearch
facebookresearchTen en cuenta que tendrás que solicitar un enlace de descarga que te debe proveer Meta. Además, existen tres modelos distintos de Llama 2, los cuales varían según su tamaño: 7B, 13B, 70B. (La «B» significa billion, y hace referencia al número de parámetros del modelo.) Mientras mayor sea la cantidad de parámetros de un modelo, la generación de texto podría ser de mejor calidad.
Sin embargo, el tiempo de respuesta también aumentará, pues requiere de mayor poder de cómputo (de ahí que es recomendable utilizar una GPU, privilegiando el paralelismo masivo de este hardware, en vez de CPU).
LangChain con Python
LangChain es un framework que nos permite interactuar con LLMs de manera fácil y rápida. El cual cuenta con dos funcionalidades principales:
- Integración de datos (llamado data-aware): conecta un LLM con otra fuente de datos, por ejemplo, todo el texto que tiene un PDF. Así permite una integración.
- Agente: interactuar directamente con el LLM, haciendo consultas y obteniendo respuestas en tu propio entorno.
Instalación en Python
Para la instalación de LangChain contamos con dos opciones: pip o conda.
Usando Pip:
pip install langchaino Conda:
conda install langchain -c conda-forgeCargando un PDF
Una posibilidad que brinda LangChain es que cuenta con varias utilidades listas para usar. Por ejemplo, cargar un PDF y extraer su texto para crear chunks. Un chunk es un fragmento de una frase que tiene alguna relación semántica. Por ejemplo:
«Mi perrita, Pole, es demasiada traviesa».
En esa frase puede agrupar en tres chunks: «Mi perrita» (que se refiere a mi mascota), «Pole» (nombre de mi mascota) y «es demasiada traviesa» (representa una característica de ella). De esta forma, los modelos LLMs, y en general en el área de procesamiento de lenguaje natural, es conveniente realizar este tipo de fragmentación pues pueden tener distinto significado semántico.
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
# solicita al usuario el path del PDF
path = input("PDF path: ")
# carga el PDF en memoria
loader = PyPDFLoader(path)
documents = loader.load()
# Divide el texto del PDF en pequeños chunks de hasta 1000 caracteres
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)Configurando la base de datos de vectores
Una base de datos de vectores es un aliado de los LLMs, pues permite almacenar y procesar las representaciones numéricas de la masiva cantidad de textos que debe analizar el modelo. Además, permite mantener el contexto histórico de las consultas que hacemos a un LLM en particular.
Para este ejemplo usaremos Pinecone que, al igual que con la carga de PDF, LangChain provee una interfaz para integrarla.
Es primordial crear primero una cuenta en Pinecode para obtener la API_KEY. Una vez estés dentro de Pinecode, debes crear el index (que es el equivalente a la BD), donde se guardaran las representaciones e interacciones que haremos con el LLM. Ten en cuenta que cuando generes el index te solicitará la dimensión del índice, para esto, puedes utilizar 768 (este tamaño depende la cantidad de texto que puede manejar la base de datos). Entonces, una vez generado el index, te asignará un entorno (ubicación) en donde se encuentra tu index, no olvides copiarlo.
Para integrar Pinecode en LangChain, el código debería ser el siguiente:
import pinecone
from langchain.vectorstores import Pinecone
from langchain.embeddings import HuggingFaceEmbeddings
pinecone.init(api_key='API_KEY', environment='ENTORNO_ASIGNADO')
# Usamos HuggingFace para transformar el texto en vectores numéricos
embeddings = HuggingFaceEmbeddings()
# Configuramos la BD en Pinecode
index_name = "chat-pdf"
index = pinecone.Index(index_name)
vectordb = Pinecone.from_documents(texts, embeddings, index_name=index_name)Cargando el modelo Llama 2
Para cargar el modelo Llama 2, al igual que pasó con la carga de PDF y Pinecode, LangChain también nos provee una interfaz (¡qué fácil!).
from langchain.llms import LlamaCpp
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
llm = LlamaCpp(
model_path="models/llama-2-13b-chat.ggmlv3.q4_0.bin",
temperature=0.75,
max_tokens=2000,
n_ctx=2048,
n_batch=512,
top_p=1,
callback_manager=callback_manager,
verbose=False,
)Nótese que en el código superior el modelo Llama 2 13B se encuentra en la carpeta models. Y, a su vez, es necesario tener un objeto CallbackManager para permitir manejar las respuestas que nos devuelva el modelo. Por otro lado, para entender en detalle cada parámetro de LlamaCpp le recomiendo leer este enlace.
Integrando todo a LangChain
Ahora nada más nos queda configurar el LLM en LangChain, para comenzar a «conversar» con este.
qa_chain = ConversationalRetrievalChain.from_llm(
llm,
vectordb.as_retriever(search_kwargs={'k': 2}),
return_source_documents=True
)El parámetro k = 2 significa el número de documentos que puede devolver nuestra base de datos en Pinecode, lo dejamos en 2, para que la respuesta no sea tan extensa. Esto no significa que devuelva dos párrafos o dos palabras, más bien, tiene que ver con los textos que el modelo considera significativo para dar una respuesta: y un documento podría contener varios párrafos.
Interactuando con el PDF
Con este hecho nada más nos falta añadir el código para interactuar con el PDF a través de nuestro LLM, Llama 2.
chat_history = []
while True:
query = input('\nSolicitud/Pregunta: ')
if query.lower() in ["exit", "quit", "q"]:
print('Exiting')
sys.exit()
result = qa_chain({'question': query, 'chat_history': chat_history})
print('Respuesta: ' + result['answer'] + '\n')
chat_history.append((query, result['answer']))La función qa_chain requiere el prompt, query, y una lista chat_history que guarda el histórico. Luego solo faltaría acceder a la respuesta del modelo en el diccionario result.
El tiempo de respuesta del modelo depende de las prestaciones que tiene su hardware.
Resultado
El prompt fue el siguiente: «Hi! Please, give me a summary», es decir, le solicité al modelo que realizará un resumen del PDF.
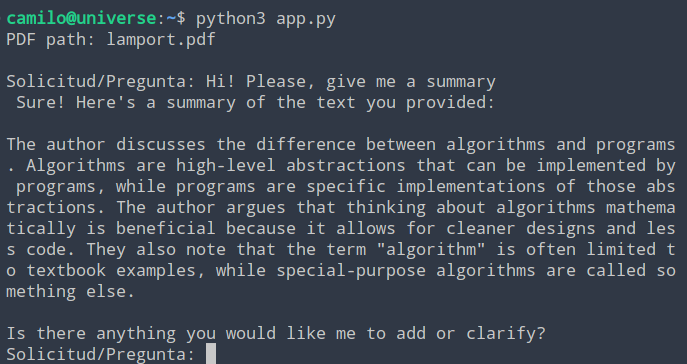
El fichero lamport.pdf corresponde a un artículo escrito por Leslie Lamport. Y tiene la típica estructura de un artículo científico. Y, como es un artículo que ya he leído, puedo decir que el resumen está bastante bien. Y abre la oportunidad para hacer muchas más cosas interesantes.Conclusión
En este artículo vimos como LangChain puede facilitar el uso de un LLM, como Llama 2, usando Python. Además, su flexibilidad de uso quedó de manifiesto al integrarlo con otras herramientas, como la base de datos de vectores Pinecode, y al cargar un PDF y extraer el texto.
Lo visto en este artículo solo es una pincelada de las capacidades de LangChain, ya que cuenta con muchas otras integraciones y, además, permite ser empleado —mediante plugins— con otros modelos como ChatGPT.
Referencias
Para seguir profundizando en LangChain, recomiendo visitar el siguiente enlace.

Y si tienes curiosidad sobre cómo funciona el LLM Llama 2, teóricamente, pues visita el siguiente artículo.


Listopro Community da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.