Cómo intercambiar mensajes entre microservicios con Apache Kafka y Golang

Aunque los microservicios han logrado revolucionar el panorama del desarrollo, brindarle mayor agilidad a los desarrolladores y reducir dependencias como bases de datos compartidas, hace falta que las distintas aplicaciones que hacen parte de ellos se integren de forma más cohesiva.
Frente a este problema, se han creado varias alternativas que se pueden categorizar según el método, sea síncrono o asíncrono. El primero utiliza APIs para intercambiar y compartir datos entre usuarios; el segundo, replica datos en una cola intermedia, así como lo hace Apache Kafka.
Requisitos para este tutorial:
- Última versión de Golang.
- Docker.
Aquí implementaremos un intercambiador de mensajes para comunicar dos microservicios con bases de datos individuales. Nuestro microservicio 1 generará un mensaje que guardará en una base de datos simulada y enviará el mismo al intercambiador de mensajes de Kafka, mientras que nuestro microservicio 2 estará a la espera de un mensaje para almacenarlo en su propia base de datos simulada.
¿Cómo funciona Apache Kafka?
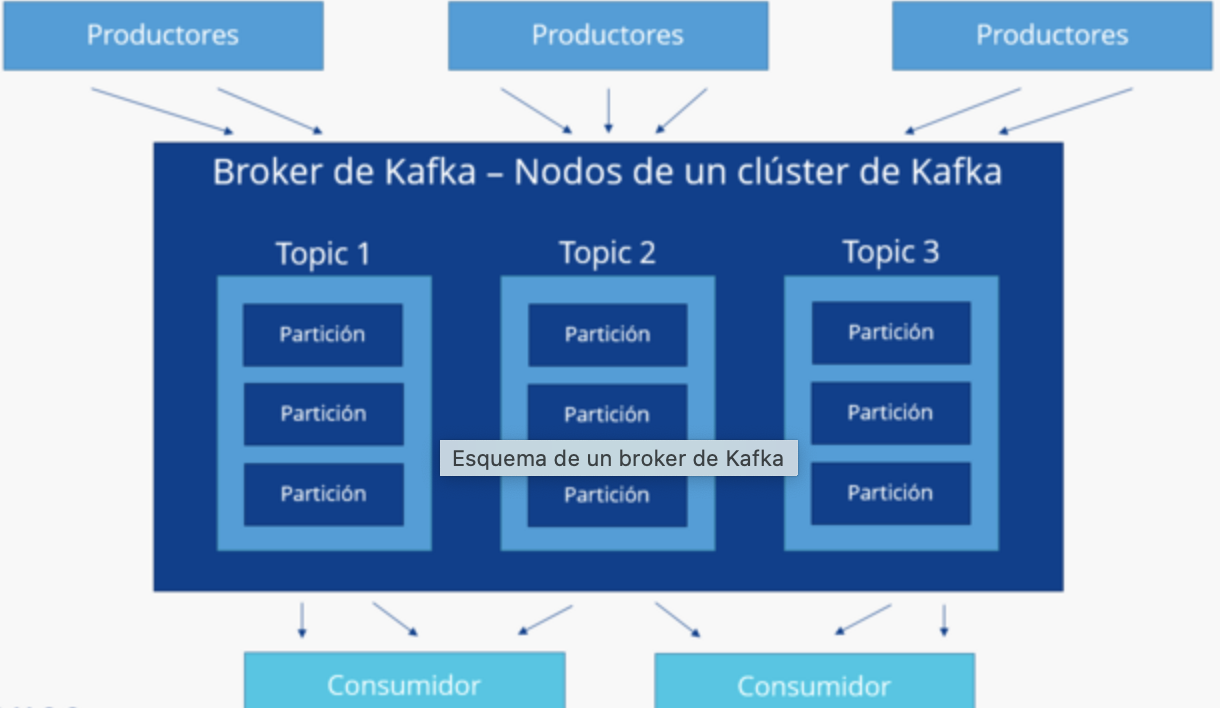
Para entender cómo funciona Apache Kafka hay que considerar algunas nociones básicas. En primer lugar, tenemos los productores, que se refieren a las aplicaciones que escriben datos en los clústeres de Kafka. Por otro lado, están los consumidores, es decir, las aplicaciones que leen estos datos en los clústeres.
Ambas partes, productores y consumidores, cuando procesan secuencias de datos acceden a un componente central en común: Kafka Streams, una biblioteca de Java. La transmisión de mensajes que se aplica en el proceso se da mediante una escritura transaccional que permite un exactly-one delivery, es decir, los mensajes se transmiten una sola vez sin duplicación.
¿Por qué Golang?
Citando a Workana (2021) "Golang, también referido como Go Programming Language, es uno de los lenguajes de programación de Open Source más recientes y, de hecho, es el que crece de forma más acelerada actualmente, ganando cada vez más popularidad entre desarrolladores. Fue desarrollado en 2007 por Ken Thompson y Rob Pike, programadores de Google quienes ya habían construido una carrera reconocida por la creación de los lenguajes de programación B y Limbo".
En sus inicios, Golang tan solo era un estándar interno de codificación para mejorar las concurrencias o tareas simultáneas de otros lenguajes. Sin embargo, con el tiempo mostró un gran potencial que permitió que se convirtiera en uno de los lenguajes de programación preferidos del mundo.
Las principales características que destacan a Golang son su escalabilidad, su eficacia y su productividad, entre otras. Por un lado, su escalabilidad hace posible aprovechar múltiples núcleos de hardware de forma escalable, a diferencia de lenguajes de programación anteriores que, no podían aprovechar los múltiples núcleos para maximizar el rendimiento pues habían sido creados cuando las computadoras sólo tenían uno. Además, pueden trabajar varios programadores en el mismo proyecto con riesgos mínimos de errores graves y modificaciones no deseadas.
Por otro lado, la estructura de Golang reduce las posibilidades de que los procesos concurrentes se desincronicen. Así, pueden usarse modelos de concurrencia distintos dependiendo del objetivo y pueden llevarse a cabo de tareas simultáneas de forma paralela. Así, se convierte en un lenguaje multiparadigma que soporta programación estructurada, funcional y orientada a objetos. Aparte de todo, Golang tiene sus propias herramientas para optimizar el uso de la memoria, como un recolector de basura.
Por último, es de destacar la accesibilidad de Golang. A primera vista ya es fácil de comprender, mantener y modificar, pues cuenta con una sintaxis muy sencilla y viene diseñado para hacer más eficaz el trabajo de programación. Funciona de forma perfecta en entornos cloud y, para mayor confianza, cuenta con candados de seguridad frente a errores y ejecuciones sospechosas.
Paso 1: Creación del proyecto

Nuestro proyecto base será una carpeta madre llamada Kafka_tutorial. En ella crearemos 3 carpetas: db, ms-consumer y ms-producer.
Paso 2: Generar un archivo docker-compose.yml en la raíz de nuestro proyecto
Este será el Docker compose que necesitaremos para nuestro tutorial. En él incluimos todas nuestras dependencias, servicios, variables de entorno e imágenes:

Paso 3: Instalación de librerías y dependencias requeridas para que nuestro tutorial funcione perfectamente
Abriremos una terminal en la raíz de nuestro proyecto y escribiremos lo siguiente:

Ahora, en la misma raíz de nuestro proyecto, escribiremos:

Iremos a nuestro archivo go.mod y daremos click en Run go mod tidy:

Ahora nuestro archivo go.mod debería lucir de esta manera:
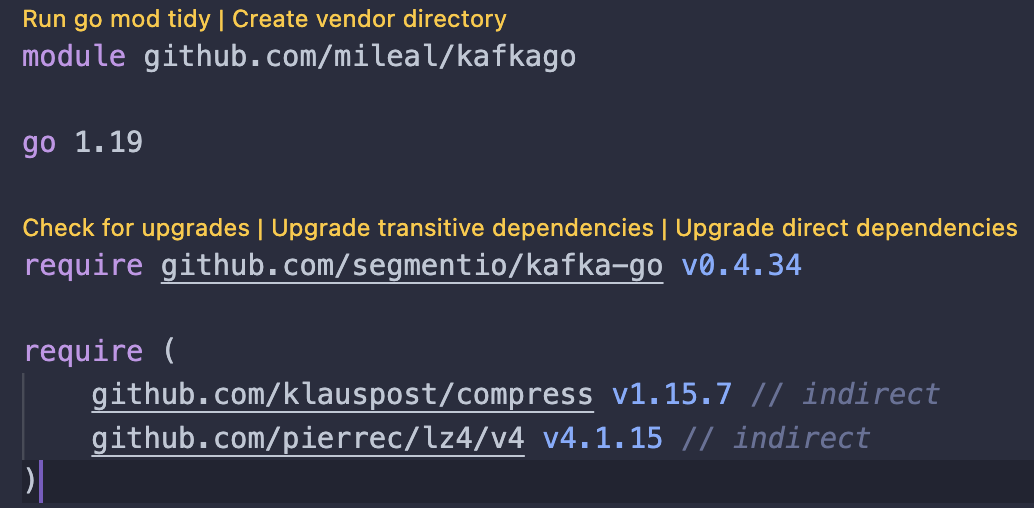

¡Nuestro proyecto va tomando forma!
Paso 4: Mensajes en bases de datos simuladas
Ahora crearemos una función que nos permitirá guardar los mensajes que produzcamos en las bases de datos simuladas. Iremos a nuestra carpeta db y crearemos un archivo db.go. A continuación escribiremos lo siguiente:

Nuestra función WriteFile toma como parámetros el nombre de la base de datos (que en nuestro caso será un archivo de texto), el tiempo en segundos que queremos que tarde en realizar la acción y, por último, el valor que queremos almacenar.
Paso 5: Creación de nuestro microservicio productor de mensajes
Ahora que tenemos toda nuestra estructura preparada y nuestra función para almacenar datos, crearemos nuestro primer microservicio productor, que se encargará de generar mensajes, almacenarlos en su base de datos y, por último, enviarlos a la cola de mensajes de Apache Kafka para que sean consumidos por nuestro microservicio consumidor.
Iremos a nuestra carpeta ms-producer y crearemos dos archivos. El primer archivo se llamará main.go, en donde irá nuestra lógica, y el segundo archivo se llamará postgres.txt, que será nuestra simulación de base de datos para el microservicio productor.

Lo primero que haremos será ir a nuestro archivo main.go y escribir:
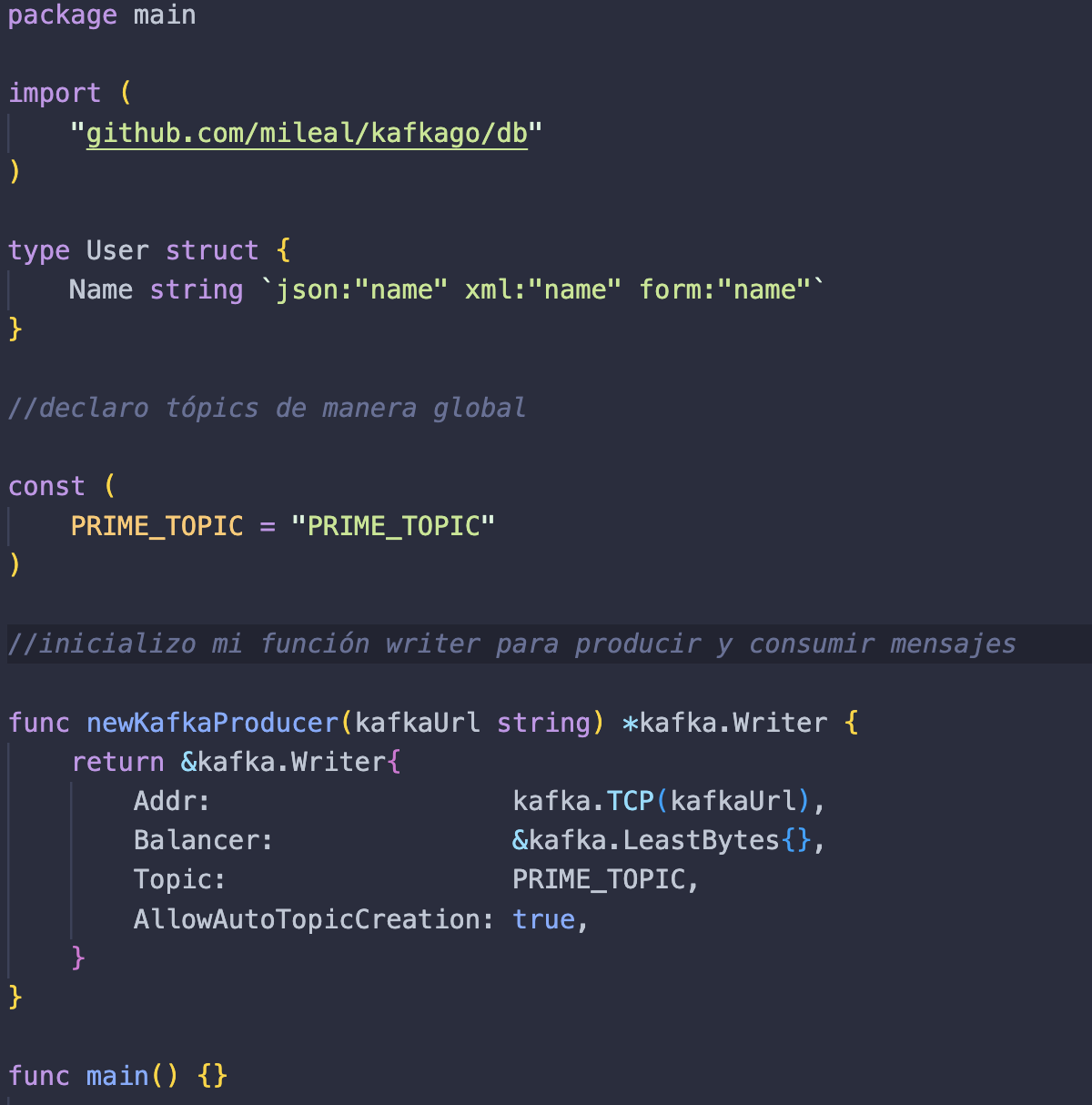
- Importaremos de nuestro módulo db. Para ello debemos escribir lo mismo que escribimos en nuestro go.mod, seguido de “/db”.
- Creamos una estructura User, que tendrá como atributo Name. Esta será la data que almacenaremos y que enviaremos a el intercambiador.
- Los mensajes en Apache Kafka no tienen un identificador, por lo que se agrupan por tópicos. Lo que haremos será crear una variable global llamada PRIME_TOPIC, que será necesaria para identificar los mensajes enviados.
- Creamos una función newKafkaProducer que nos servirá para realizar la configuración de nuestro productor.
Ahora desarrollaremos la lógica. Para ello, construimos nuestra función main de la siguiente forma:
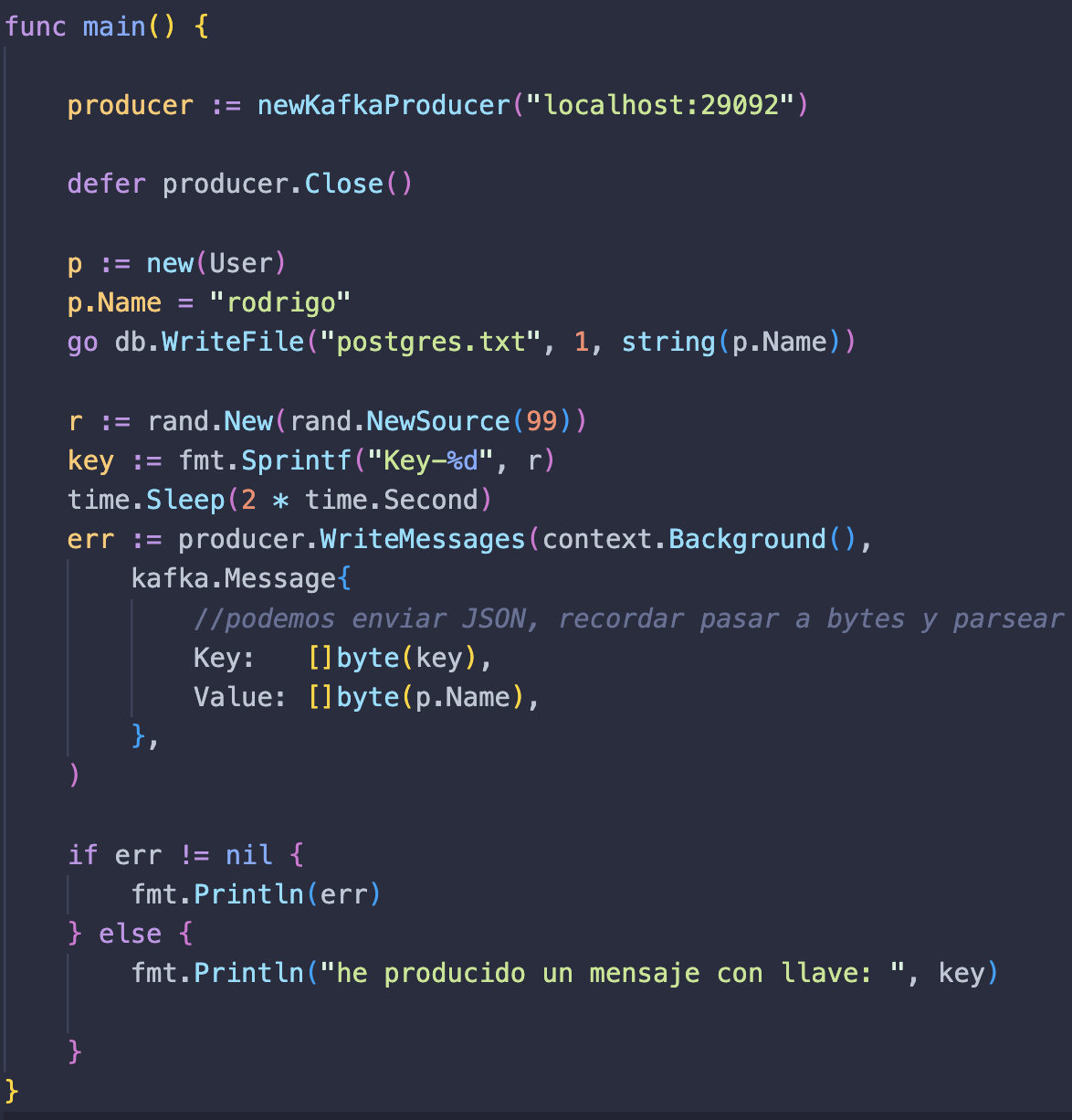
Inicializamos nuestra función newKafkaProducer con la url localhost:29092, que es donde está alojada nuestra imagen de Kafka. Instanciamos un usuario “p” y le damos el nombre de rodrigo. Ahora utilizaremos la función db.WriteFile que creamos en nuestra carpeta db y le pasamos nuestra base de datos postgrest.txt, dándole un segundo para que realice la escritura y el valor de nuestro dato, que en este caso es p.Name convertido a cadena de texto.
Creamos una variable “r” de tipo numérica de valor aleatorio para darle un identificador a nuestro mensaje; añadimos ese valor a nuestra variable key. Ahora que almacenamos el mensaje en nuestra base de datos “postgres” haremos el envío del mensaje a la cola de Kafka. Para ello usamos la función producer.WriteMessages, donde le pasamos un objeto de tipo kafka.Message con nuestra llave y valor. Por último, imprimimos un log que nos confirma que el mensaje ha sido producido y enviado.
Al ejecutar nuestro archivo main.go obtenemos una respuesta positiva:

Si revisamos nuestro archivo postgres.txt veremos que el mensaje rodrigo se guardó correctamente:

Paso 6: Creación de nuestro microservicio consumidor de mensajes
Ahora que tenemos mensajes en la cola de Kafka, lo que nos queda es poder consumirlos desde otro microservicio. Para esto, iremos a nuestra carpeta ms-consumer y crearemos dos archivos: uno será main.go, donde escribiremos toda la lógica necesaria para nuestro consumidor, y el otro será nuestra base de datos simulada para este microservicio que se llamará elasticsearch.json.

Ahora iremos a nuestro archivo main.go de nuestra carpeta consumer y escribiremos:
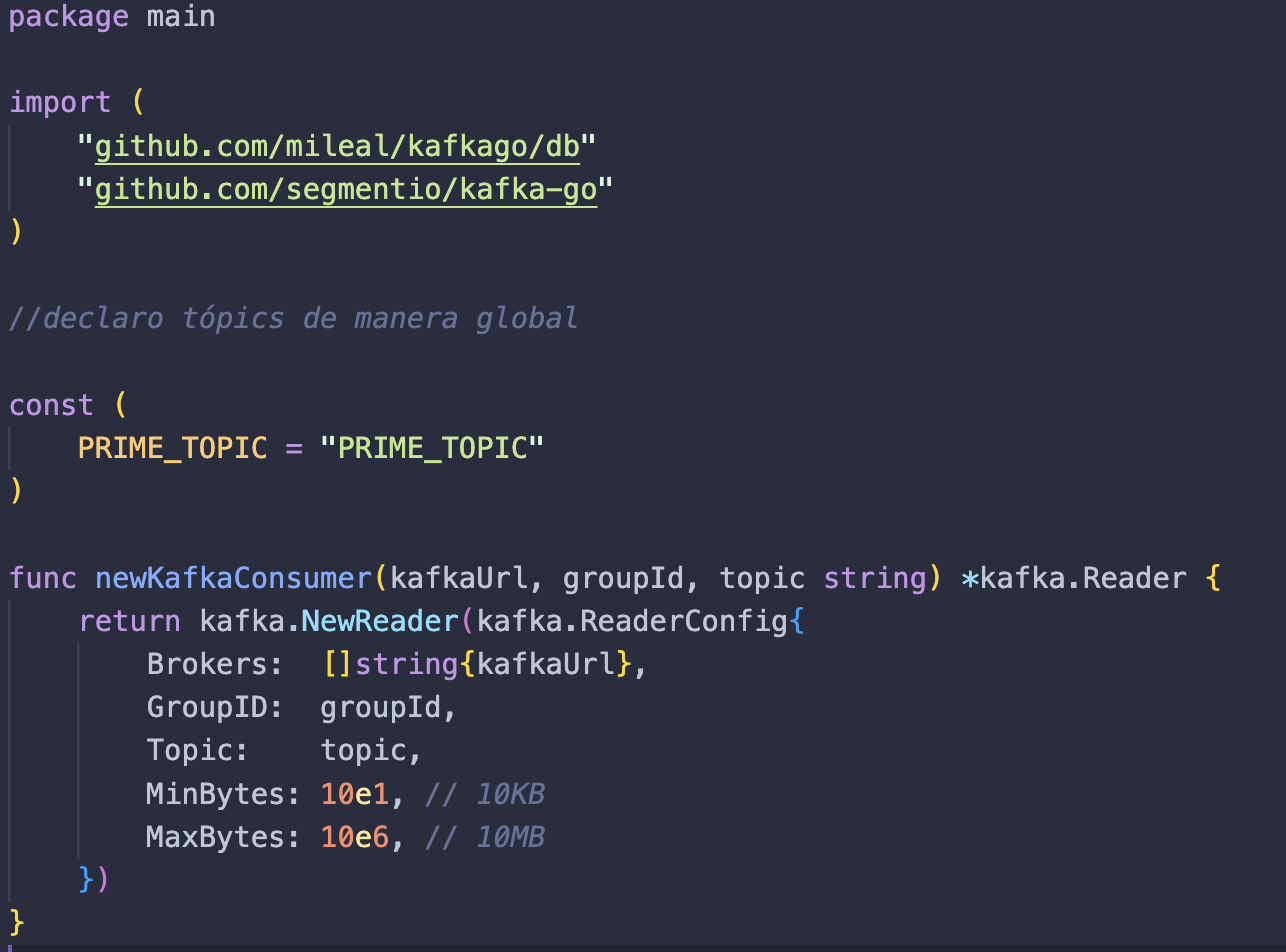
Primero importamos lo necesario. Hacemos casi la misma configuración que en nuestro archivo producer, pero lo que haremos diferente será nuestra nueva función newKafkaConsumer, que recibe como parámetros una url, un grupo de consumidores y un tópico, hacemos la configuración inicial de nuestra función NewReader usando la función ReaderConfig.
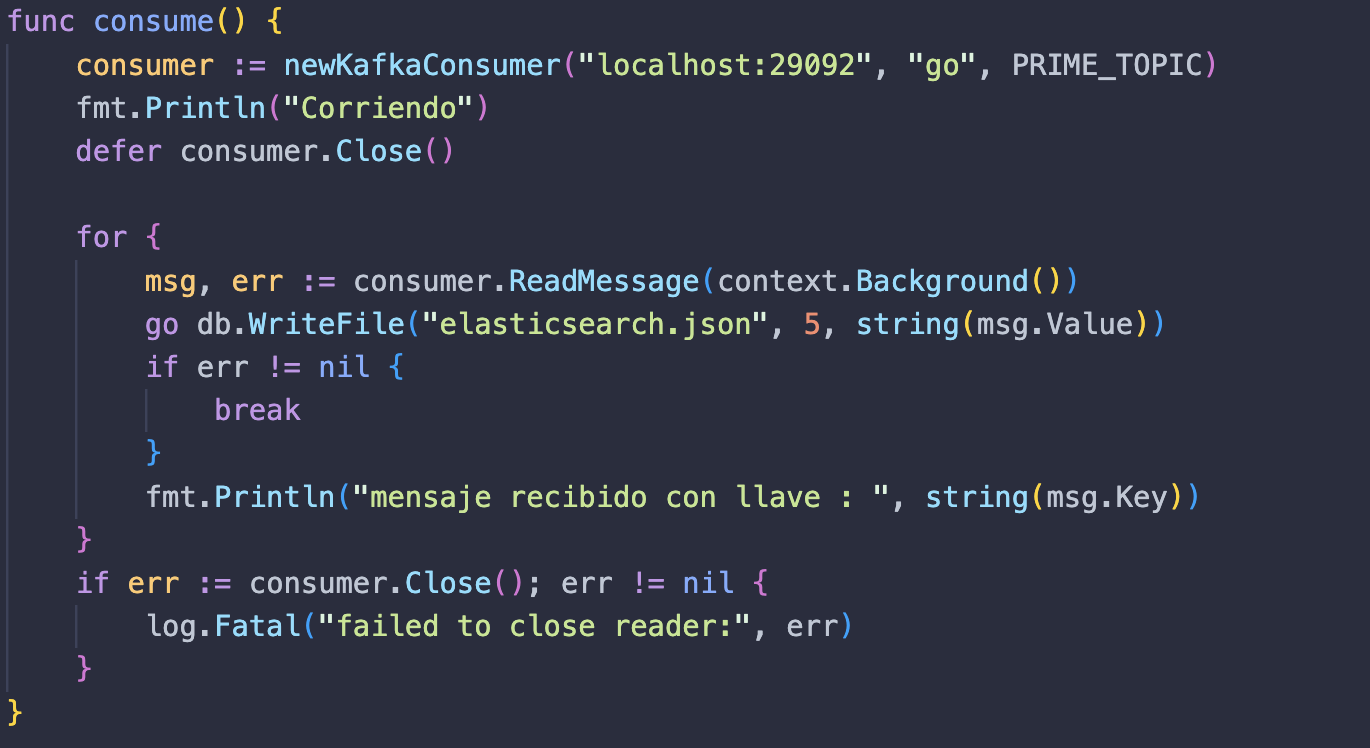
Ahora crearemos una función consume, encargada de almacenar toda la lógica correspondiente a consumir mensajes de la cola y escribirlos en la base de datos. Primero instanciamos nuestra función newKafkaConsumer a la que le pasamos la url localhost:29092, un grupo de consumidores llamado go y un tópico llamado PRIME_TOPIC.
Creamos un ciclo infinito para escanear la cola constantemente en busca de nuevos mensajes. Para ello, primero creamos una variable msg que será el mensaje en la cola, luego ejecutamos una go routine con nuestra función WriteFile para escribir los mensajes en nuestra base de datos simulada elasticsearch con 5 segundos de retraso para que podamos ver el funcionamiento y, por último, imprimimos un log en caso de que recibamos un mensaje y otro en caso de que algo falle.
Llamamos a consume en nuestra función main y ¡nuestro proyecto está listo!

Al ejecutar ambos microservicios podemos ver cómo podemos intercambiar mensajes entre ellos.


¡Eso es todo! Espero que este tutorial haya sido de utilidad. ¡Hasta pronto!
Revelo Content Network da la bienvenida a todas las razas, etnias, nacionalidades, credos, géneros, orientaciones, puntos de vista e ideologías, siempre y cuando promuevan la diversidad, la equidad, la inclusión y el crecimiento profesional de los profesionales en tecnología.